 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Similarity-Based One-Shot Clustering for Multi-Task Hierarchical Federated Learning
Paper and Code
Oct 03, 2024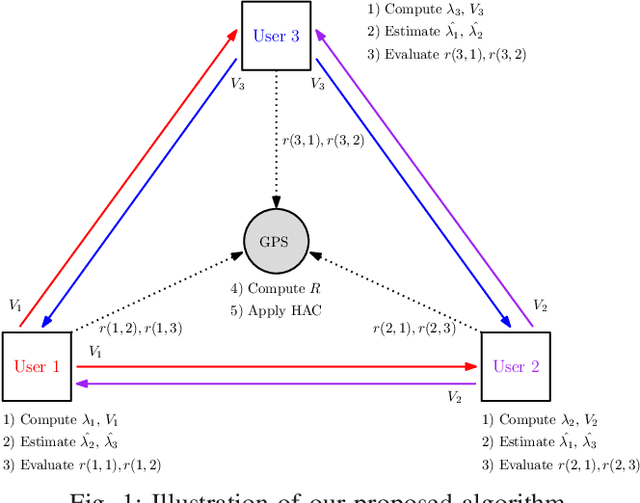
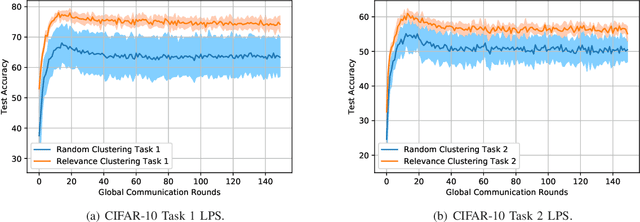
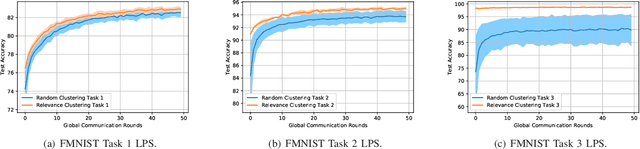
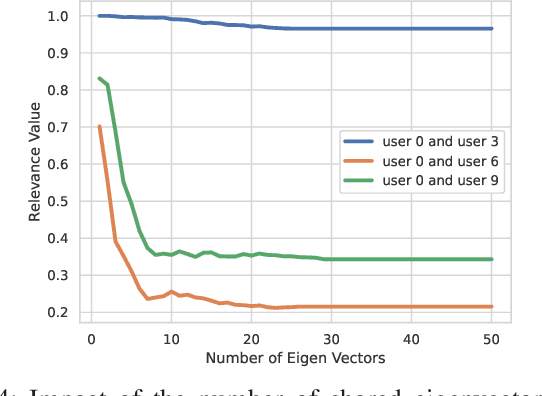
We address the problem of cluster identity estimation in a hierarchical federated learning setting in which users work toward learning different tasks. To overcome the challenge of task heterogeneity, users need to be grouped in a way such that users with the same task are in the same group, conducting training together, while sharing the weights of feature extraction layers with the other groups. Toward that end, we propose a one-shot clustering algorithm that can effectively identify and group users based on their data similarity. This enables more efficient collaboration and sharing of a common layer representation within the federated learning system. Our proposed algorithm not only enhances the clustering process, but also overcomes challenges related to privacy concerns, communication overhead, and the need for prior knowledge about learning models or loss function behaviors. We validate our proposed algorithm using various datasets such as CIFAR-10 and Fashion MNIST, and show that it outperforms the baseline in terms of accuracy and variance reduction.