 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSIR: Spectral Client Identification and Relabeling for Federated Learning with Noisy Labels
Apr 22, 2026Federated learning (FL) enables collaborative model training without sharing raw data; however, the presence of noisy labels across distributed clients can severely degrade the learning performance. In this paper, we propose FedSIR, a multi-stage framework for robust FL under noisy labels. Different from existing approaches that mainly rely on designing noise-tolerant loss functions or exploiting loss dynamics during training, our method leverages the spectral structure of client feature representations to identify and mitigate label noise. Our framework consists of three key components. First, we identify clean and noisy clients by analyzing the spectral consistency of class-wise feature subspaces with minimal communication overhead. Second, clean clients provide spectral references that enable noisy clients to relabel potentially corrupted samples using both dominant class directions and residual subspaces. Third, we employ a noise-aware training strategy that integrates logit-adjusted loss, knowledge distillation, and distance-aware aggregation to further stabilize federated optimization. Extensive experiments on standard FL benchmarks demonstrate that FedSIR consistently outperforms state-of-the-art methods for FL with noisy labels. The code is available at https://github.com/sinagh72/FedSIR.
FB-NLL: A Feature-Based Approach to Tackle Noisy Labels in Personalized Federated Learning
Apr 21, 2026Personalized Federated Learning (PFL) aims to learn multiple task-specific models rather than a single global model across heterogeneous data distributions. Existing PFL approaches typically rely on iterative optimization-such as model update trajectories-to cluster users that need to accomplish the same tasks together. However, these learning-dynamics-based methods are inherently vulnerable to low-quality data and noisy labels, as corrupted updates distort clustering decisions and degrade personalization performance. To tackle this, we propose FB-NLL, a feature-centric framework that decouples user clustering from iterative training dynamics. By exploiting the intrinsic heterogeneity of local feature spaces, FB-NLL characterizes each user through the spectral structure of the covariances of their feature representations and leverages subspace similarity to identify task-consistent user groupings. This geometry-aware clustering is label-agnostic and is performed in a one-shot manner prior to training, significantly reducing communication overhead and computational costs compared to iterative baselines. Complementing this, we introduce a feature-consistency-based detection and correction strategy to address noisy labels within clusters. By leveraging directional alignment in the learned feature space and assigning labels based on class-specific feature subspaces, our method mitigates corrupted supervision without requiring estimation of stochastic noise transition matrices. In addition, FB-NLL is model-independent and integrates seamlessly with existing noise-robust training techniques. Extensive experiments across diverse datasets and noise regimes demonstrate that our framework consistently outperforms state-of-the-art baselines in terms of average accuracy and performance stability.
RCC-PFL: Robust Client Clustering under Noisy Labels in Personalized Federated Learning
Mar 25, 2025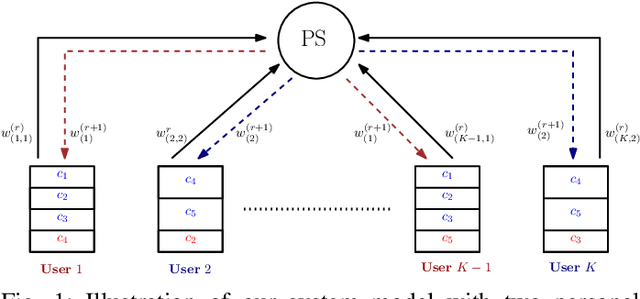
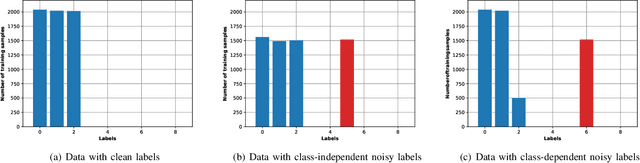
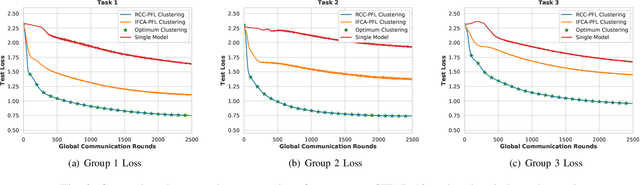
We address the problem of cluster identity estimation in a personalized federated learning (PFL) setting in which users aim to learn different personal models. The backbone of effective learning in such a setting is to cluster users into groups whose objectives are similar. A typical approach in the literature is to achieve this by training users' data on different proposed personal models and assign them to groups based on which model achieves the lowest value of the users' loss functions. This process is to be done iteratively until group identities converge. A key challenge in such a setting arises when users have noisy labeled data, which may produce misleading values of their loss functions, and hence lead to ineffective clustering. To overcome this challenge, we propose a label-agnostic data similarity-based clustering algorithm, coined RCC-PFL, with three main advantages: the cluster identity estimation procedure is independent from the training labels; it is a one-shot clustering algorithm performed prior to the training; and it requires fewer communication rounds and less computation compared to iterative-based clustering methods. We validate our proposed algorithm using various models and datasets and show that it outperforms multiple baselines in terms of average accuracy and variance reduction.
Data Similarity-Based One-Shot Clustering for Multi-Task Hierarchical Federated Learning
Oct 03, 2024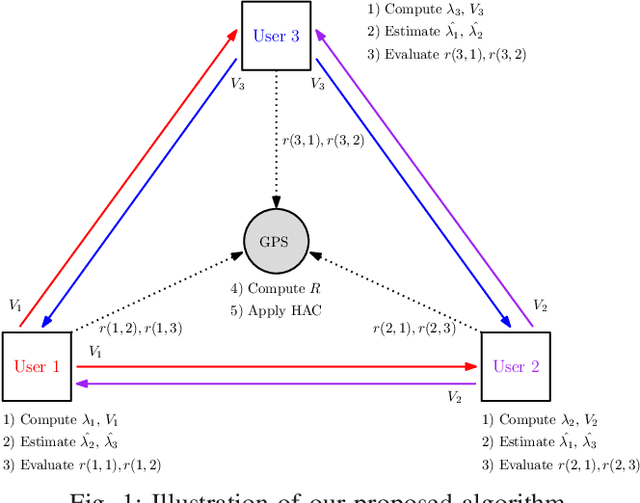
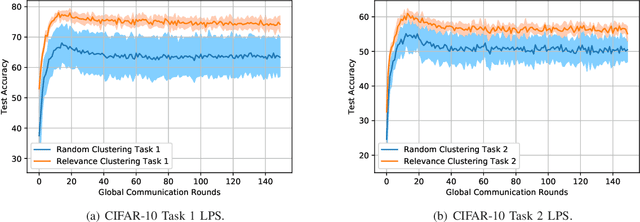
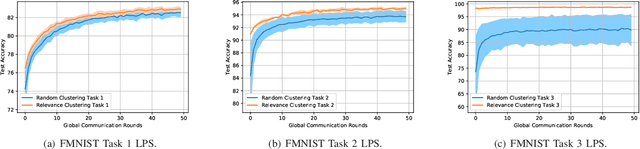
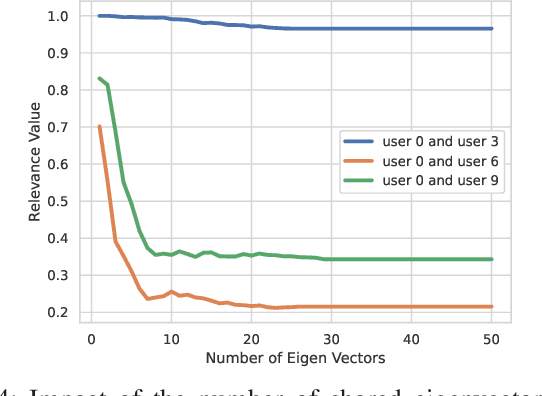
We address the problem of cluster identity estimation in a hierarchical federated learning setting in which users work toward learning different tasks. To overcome the challenge of task heterogeneity, users need to be grouped in a way such that users with the same task are in the same group, conducting training together, while sharing the weights of feature extraction layers with the other groups. Toward that end, we propose a one-shot clustering algorithm that can effectively identify and group users based on their data similarity. This enables more efficient collaboration and sharing of a common layer representation within the federated learning system. Our proposed algorithm not only enhances the clustering process, but also overcomes challenges related to privacy concerns, communication overhead, and the need for prior knowledge about learning models or loss function behaviors. We validate our proposed algorithm using various datasets such as CIFAR-10 and Fashion MNIST, and show that it outperforms the baseline in terms of accuracy and variance reduction.
Delay Sensitive Hierarchical Federated Learning with Stochastic Local Updates
Feb 09, 2023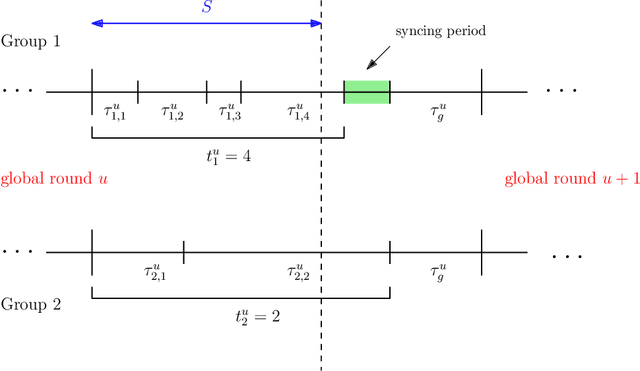
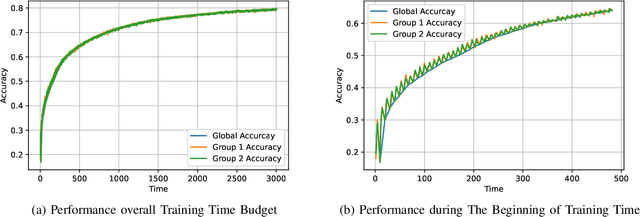
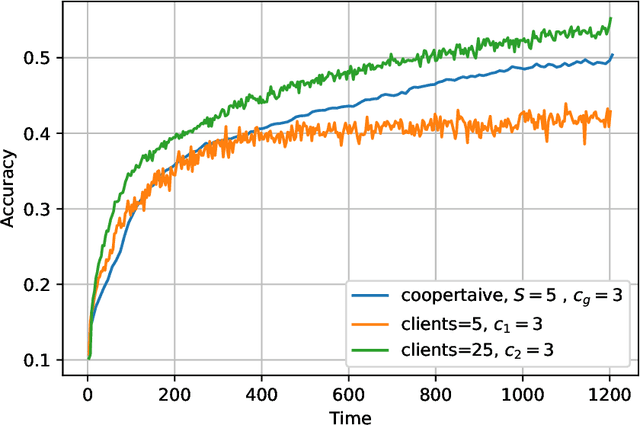
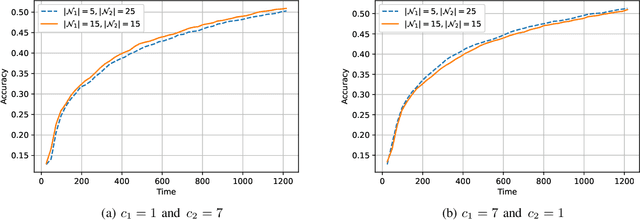
The impact of local averaging on the performance of federated learning (FL) systems is studied in the presence of communication delay between the clients and the parameter server. To minimize the effect of delay, clients are assigned into different groups, each having its own local parameter server (LPS) that aggregates its clients' models. The groups' models are then aggregated at a global parameter server (GPS) that only communicates with the LPSs. Such setting is known as hierarchical FL (HFL). Different from most works in the literature, the number of local and global communication rounds in our work is randomly determined by the (different) delays experienced by each group of clients. Specifically, the number of local averaging rounds are tied to a wall-clock time period coined the sync time $S$, after which the LPSs synchronize their models by sharing them with the GPS. Such sync time $S$ is then reapplied until a global wall-clock time is exhausted.