 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mathematical Rules with Large Language Models
Oct 24, 2024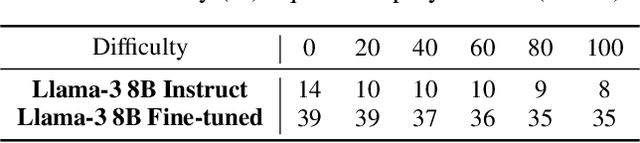

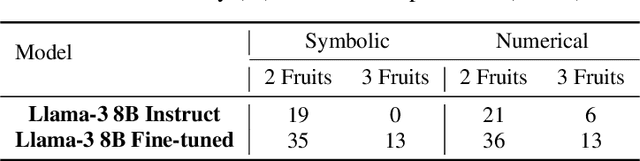

In this paper, we study the ability of large language models to learn specific mathematical rules such as distributivity or simplifying equations. We present an empirical analysis of their ability to generalize these rules, as well as to reuse them in the context of word problems. For this purpose, we provide a rigorous methodology to build synthetic data incorporating such rules, and perform fine-tuning of large language models on such data. Our experiments show that our model can learn and generalize these rules to some extent, as well as suitably reuse them in the context of word problems.
Correlated Quantization for Faster Nonconvex Distributed Optimization
Jan 10, 2024Quantization (Alistarh et al., 2017) is an important (stochastic) compression technique that reduces the volume of transmitted bits during each communication round in distributed model training. Suresh et al. (2022) introduce correlated quantizers and show their advantages over independent counterparts by analyzing distributed SGD communication complexity. We analyze the forefront distributed non-convex optimization algorithm MARINA (Gorbunov et al., 2022) utilizing the proposed correlated quantizers and show that it outperforms the original MARINA and distributed SGD of Suresh et al. (2022) with regard to the communication complexity. We significantly refine the original analysis of MARINA without any additional assumptions using the weighted Hessian variance (Tyurin et al., 2022), and then we expand the theoretical framework of MARINA to accommodate a substantially broader range of potentially correlated and biased compressors, thus dilating the applicability of the method beyond the conventional independent unbiased compressor setup. Extensive experimental results corroborate our theoretical findings.
Communication Compression for Byzantine Robust Learning: New Efficient Algorithms and Improved Rates
Oct 15, 2023



Byzantine robustness is an essential feature of algorithms for certain distributed optimization problems, typically encountered in collaborative/federated learning. These problems are usually huge-scale, implying that communication compression is also imperative for their resolution. These factors have spurred recent algorithmic and theoretical developments in the literature of Byzantine-robust learning with compression. In this paper, we contribute to this research area in two main directions. First, we propose a new Byzantine-robust method with compression -- Byz-DASHA-PAGE -- and prove that the new method has better convergence rate (for non-convex and Polyak-Lojasiewicz smooth optimization problems), smaller neighborhood size in the heterogeneous case, and tolerates more Byzantine workers under over-parametrization than the previous method with SOTA theoretical convergence guarantees (Byz-VR-MARINA). Secondly, we develop the first Byzantine-robust method with communication compression and error feedback -- Byz-EF21 -- along with its bidirectional compression version -- Byz-EF21-BC -- and derive the convergence rates for these methods for non-convex and Polyak-Lojasiewicz smooth case. We test the proposed methods and illustrate our theoretical findings in the numerical experiments.