Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mathematical Rules with Large Language Models
Paper and Code
Oct 24, 2024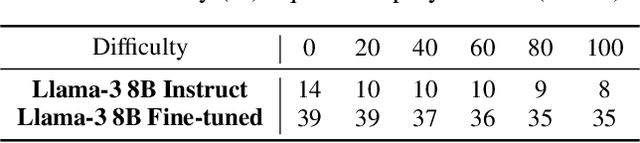

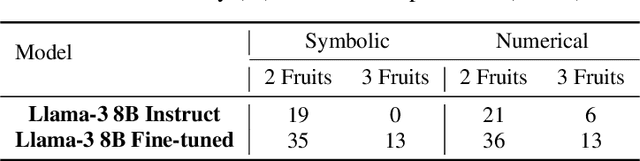

In this paper, we study the ability of large language models to learn specific mathematical rules such as distributivity or simplifying equations. We present an empirical analysis of their ability to generalize these rules, as well as to reuse them in the context of word problems. For this purpose, we provide a rigorous methodology to build synthetic data incorporating such rules, and perform fine-tuning of large language models on such data. Our experiments show that our model can learn and generalize these rules to some extent, as well as suitably reuse them in the context of word problems.
* NeurIPS'24 MATH-AI, the 4th Workshop on Mathematical Reasoning and AI
View paper on