 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Face Image Retrieval: a Comparative Study with Dictionary Learning
Dec 13, 2018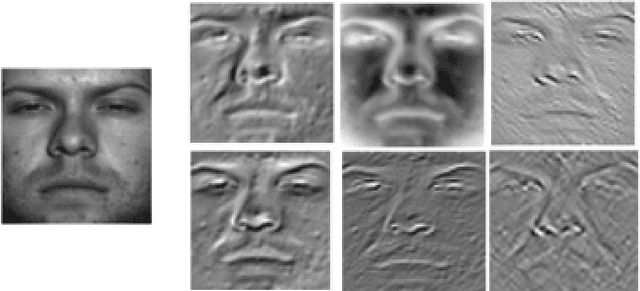
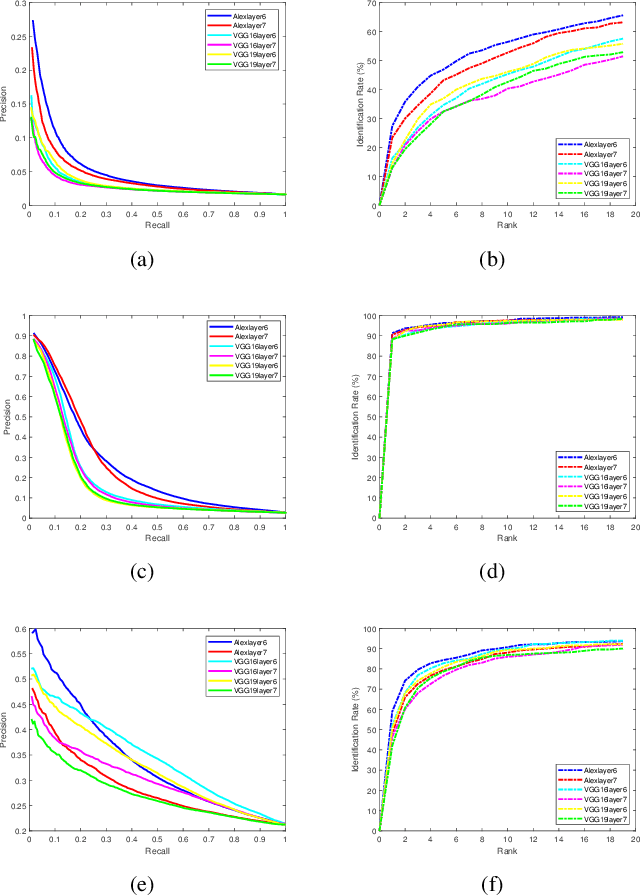
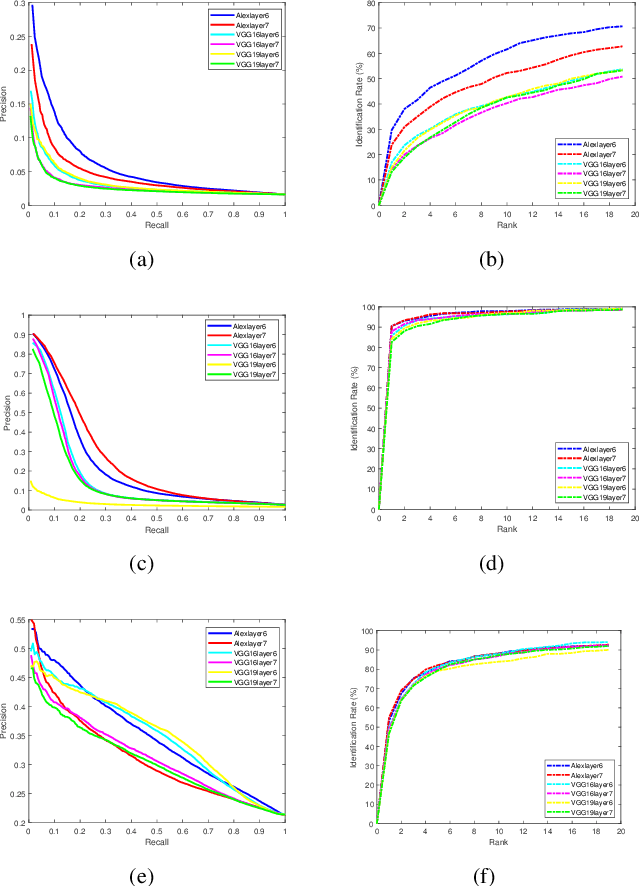
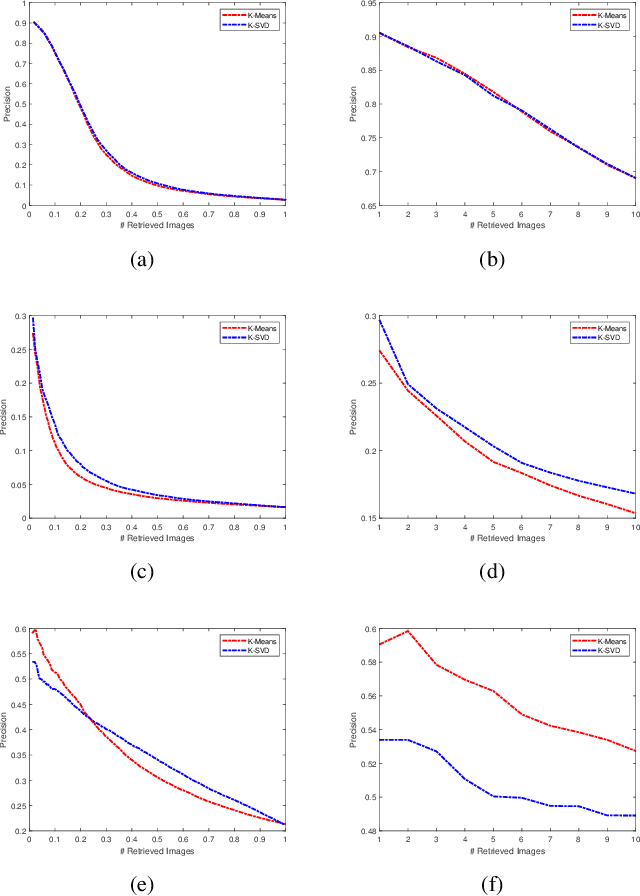
Facial image retrieval is a challenging task since faces have many similar features (areas), which makes it difficult for the retrieval systems to distinguish faces of different people. With the advent of deep learning, deep networks are often applied to extract powerful features that are used in many areas of computer vision. This paper investigates the application of different deep learning models for face image retrieval, namely, Alexlayer6, Alexlayer7, VGG16layer6, VGG16layer7, VGG19layer6, and VGG19layer7, with two types of dictionary learning techniques, namely $K$-means and $K$-SVD. We also investigate some coefficient learning techniques such as the Homotopy, Lasso, Elastic Net and SSF and their effect on the face retrieval system. The comparative results of the experiments conducted on three standard face image datasets show that the best performers for face image retrieval are Alexlayer7 with $K$-means and SSF, Alexlayer6 with $K$-SVD and SSF, and Alexlayer6 with $K$-means and SSF. The APR and ARR of these methods were further compared to some of the state of the art methods based on local descriptors. The experimental results show that deep learning outperforms most of those methods and therefore can be recommended for use in practice of face image retrieval
Improving TSP Solutions Using GA with a New Hybrid Mutation Based on Knowledge and Randomness
Jan 22, 2018

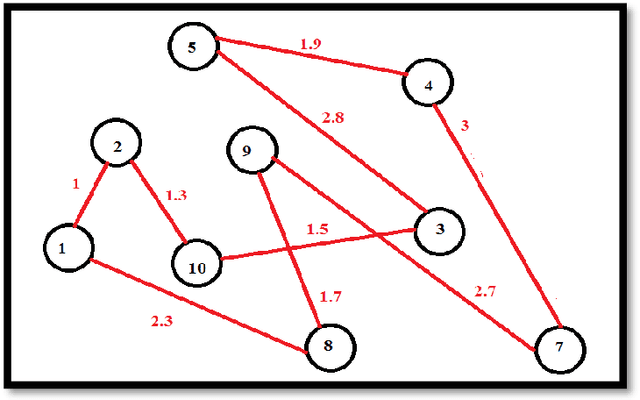
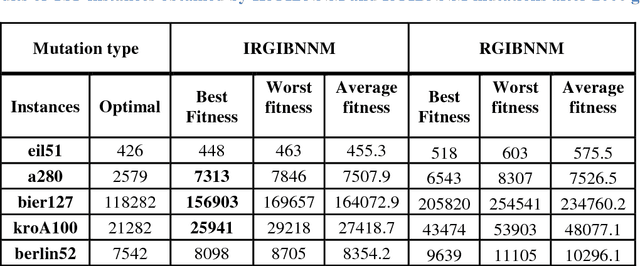
Genetic algorithm (GA) is an efficient tool for solving optimization problems by evolving solutions, as it mimics the Darwinian theory of natural evolution. The mutation operator is one of the key success factors in GA, as it is considered the exploration operator of GA. Various mutation operators exist to solve hard combinatorial problems such as the TSP. In this paper, we propose a hybrid mutation operator called "IRGIBNNM", this mutation is a combination of two existing mutations, a knowledge-based mutation, and a random-based mutation. We also improve the existing "select best mutation" strategy using the proposed mutation. We conducted several experiments on twelve benchmark Symmetric traveling salesman problem (STSP) instances. The results of our experiments show the efficiency of the proposed mutation, particularly when we use it with some other mutations. Keyword: Knowledge-based mutation, Inversion mutation, Slide mutation, RGIBNNM, SBM.
Enhancing Genetic Algorithms using Multi Mutations
Jan 10, 2018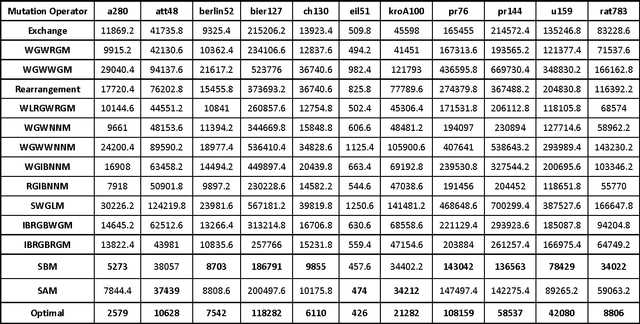
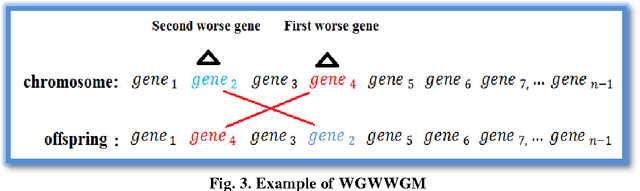
Mutation is one of the most important stages of the genetic algorithm because of its impact on the exploration of global optima, and to overcome premature convergence. There are many types of mutation, and the problem lies in selection of the appropriate type, where the decision becomes more difficult and needs more trial and error. This paper investigates the use of more than one mutation operator to enhance the performance of genetic algorithms. Novel mutation operators are proposed, in addition to two selection strategies for the mutation operators, one of which is based on selecting the best mutation operator and the other randomly selects any operator. Several experiments on some Travelling Salesman Problems (TSP) were conducted to evaluate the proposed methods, and these were compared to the well-known exchange mutation and rearrangement mutation. The results show the importance of some of the proposed methods, in addition to the significant enhancement of the genetic algorithm's performance, particularly when using more than one mutation operator.
* 17 pages, 11 figures, 1 table, 41 references
On Enhancing Genetic Algorithms Using New Crossovers
Jan 08, 2018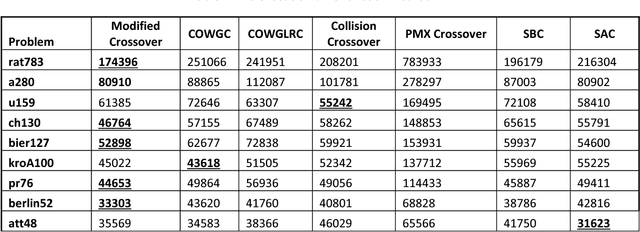



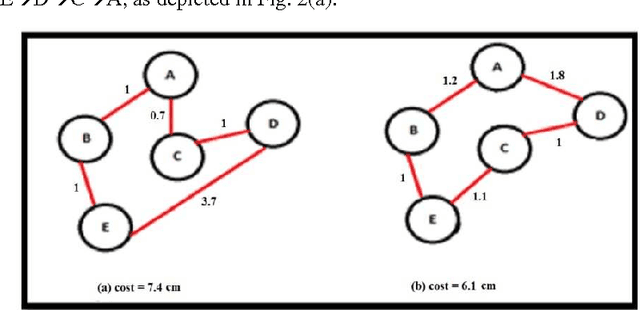
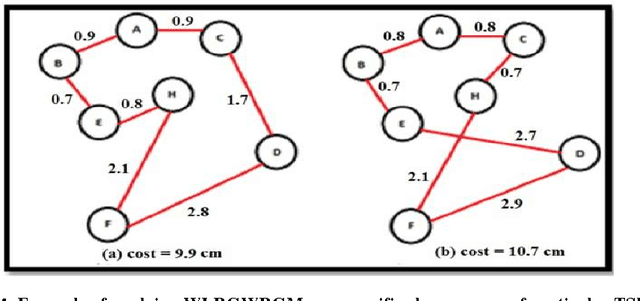
This paper investigates the use of more than one crossover operator to enhance the performance of genetic algorithms. Novel crossover operators are proposed such as the Collision crossover, which is based on the physical rules of elastic collision, in addition to proposing two selection strategies for the crossover operators, one of which is based on selecting the best crossover operator and the other randomly selects any operator. Several experiments on some Travelling Salesman Problems (TSP) have been conducted to evaluate the proposed methods, which are compared to the well-known Modified crossover operator and partially mapped Crossover (PMX) crossover. The results show the importance of some of the proposed methods, such as the collision crossover, in addition to the significant enhancement of the genetic algorithms performance, particularly when using more than one crossover operator.
* 15 pages and 11 figure
Distance and Similarity Measures Effect on the Performance of K-Nearest Neighbor Classifier - A Review
Aug 14, 2017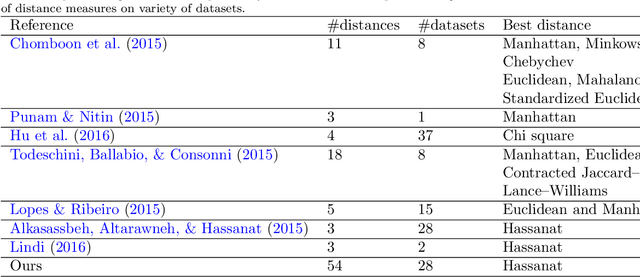



The K-nearest neighbor (KNN) classifier is one of the simplest and most common classifiers, yet its performance competes with the most complex classifiers in the literature. The core of this classifier depends mainly on measuring the distance or similarity between the tested example and the training examples. This raises a major question about which distance measures to be used for the KNN classifier among a large number of distance and similarity measures? This review attempts to answer the previous question through evaluating the performance (measured by accuracy, precision and recall) of the KNN using a large number of distance measures, tested on a number of real world datasets, with and without adding different levels of noise. The experimental results show that the performance of KNN classifier depends significantly on the distance used, the results showed large gaps between the performances of different distances. We found that a recently proposed non-convex distance performed the best when applied on most datasets comparing to the other tested distances. In addition, the performance of the KNN degraded only about $20\%$ while the noise level reaches $90\%$, this is true for all the distances used. This means that the KNN classifier using any of the top $10$ distances tolerate noise to a certain degree. Moreover, the results show that some distances are less affected by the added noise comparing to other distances.
Victory Sign Biometric for Terrorists Identification
Feb 26, 2016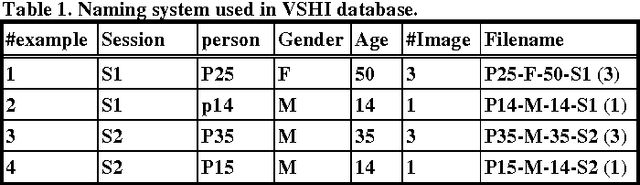


Covering the face and all body parts, sometimes the only evidence to identify a person is their hand geometry, and not the whole hand- only two fingers (the index and the middle fingers) while showing the victory sign, as seen in many terrorists videos. This paper investigates for the first time a new way to identify persons, particularly (terrorists) from their victory sign. We have created a new database in this regard using a mobile phone camera, imaging the victory signs of 50 different persons over two sessions. Simple measurements for the fingers, in addition to the Hu Moments for the areas of the fingers were used to extract the geometric features of the shown part of the hand shown after segmentation. The experimental results using the KNN classifier were encouraging for most of the recorded persons; with about 40% to 93% total identification accuracy, depending on the features, distance metric and K used.
Rule-and Dictionary-based Solution for Variations in Written Arabic Names in Social Networks, Big Data, Accounting Systems and Large Databases
Feb 18, 2015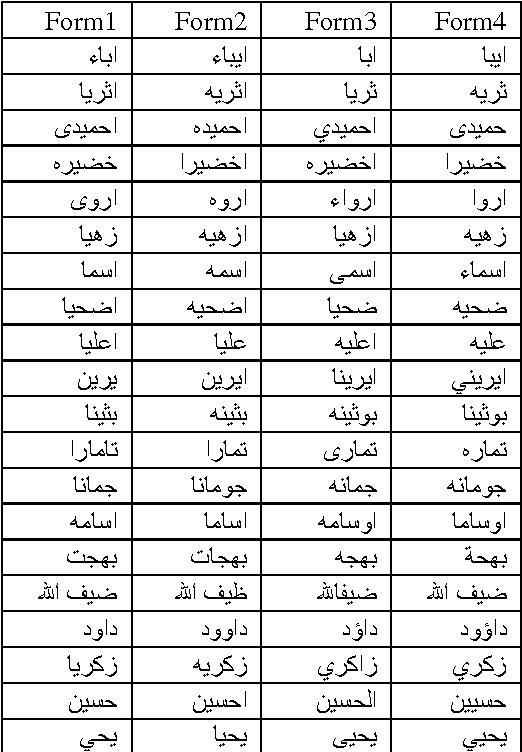
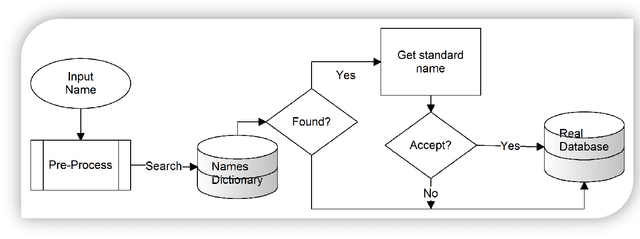
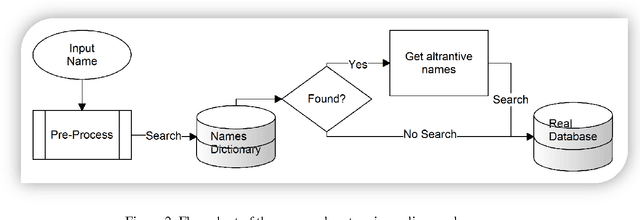
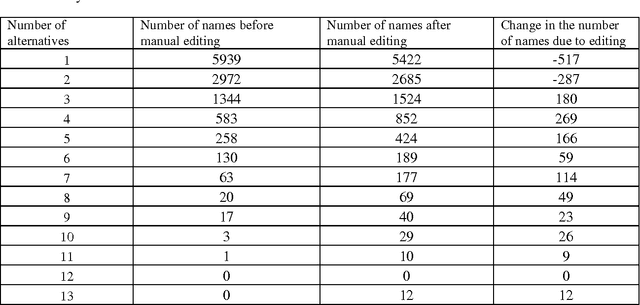
This paper investigates the problem that some Arabic names can be written in multiple ways. When someone searches for only one form of a name, neither exact nor approximate matching is appropriate for returning the multiple variants of the name. Exact matching requires the user to enter all forms of the name for the search, and approximate matching yields names not among the variations of the one being sought. In this paper, we attempt to solve the problem with a dictionary of all Arabic names mapped to their different (alternative) writing forms. We generated alternatives based on rules we derived from reviewing the first names of 9.9 million citizens and former citizens of Jordan. This dictionary can be used for both standardizing the written form when inserting a new name into a database and for searching for the name and all its alternative written forms. Creating the dictionary automatically based on rules resulted in at least 7% erroneous acceptance errors and 7.9% erroneous rejection errors. We addressed the errors by manually editing the dictionary. The dictionary can be of help to real world-databases, with the qualification that manual editing does not guarantee 100% correctness.
On Enhancing The Performance Of Nearest Neighbour Classifiers Using Hassanat Distance Metric
Jan 04, 2015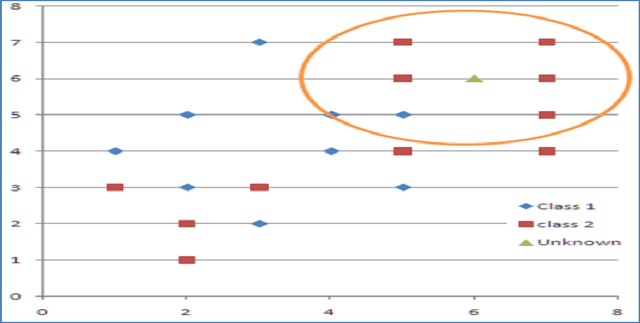
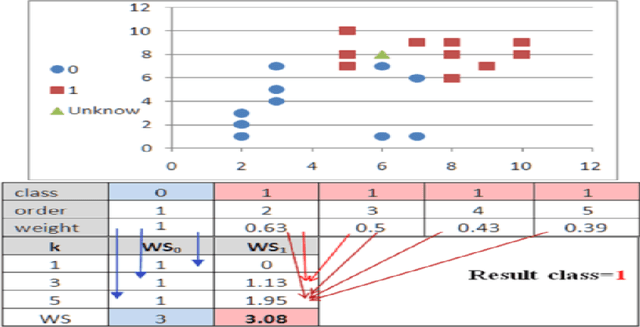
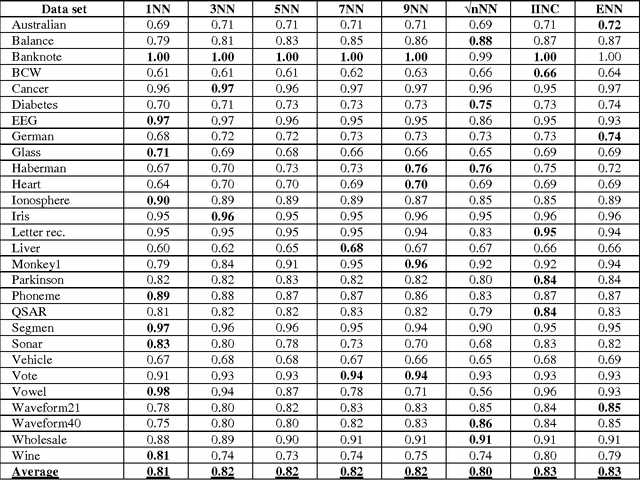
We showed in this work how the Hassanat distance metric enhances the performance of the nearest neighbour classifiers. The results demonstrate the superiority of this distance metric over the traditional and most-used distances, such as Manhattan distance and Euclidian distance. Moreover, we proved that the Hassanat distance metric is invariant to data scale, noise and outliers. Throughout this work, it is clearly notable that both ENN and IINC performed very well with the distance investigated, as their accuracy increased significantly by 3.3% and 3.1% respectively, with no significant advantage of the ENN over the IINC in terms of accuracy. Correspondingly, it can be noted from our results that there is no optimal algorithm that can solve all real-life problems perfectly; this is supported by the no-free-lunch theorem
Visual Speech Recognition
Sep 03, 2014
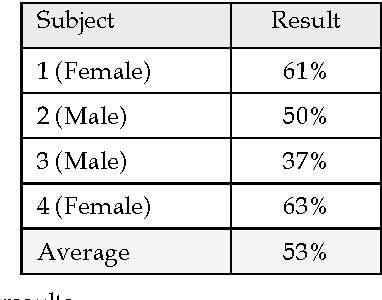
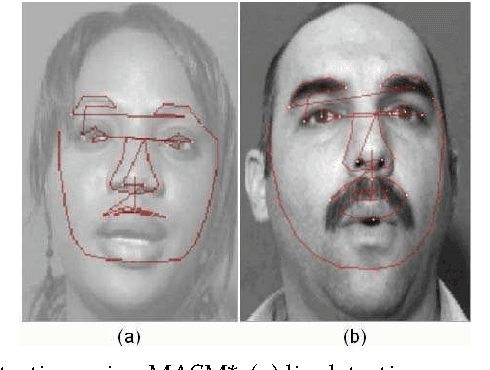
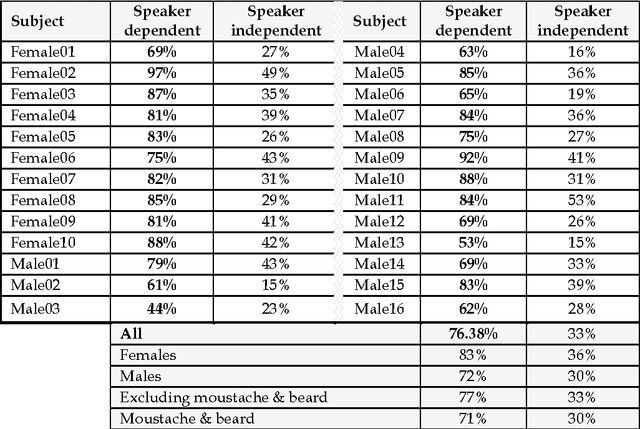
Lip reading is used to understand or interpret speech without hearing it, a technique especially mastered by people with hearing difficulties. The ability to lip read enables a person with a hearing impairment to communicate with others and to engage in social activities, which otherwise would be difficult. Recent advances in the fields of computer vision, pattern recognition, and signal processing has led to a growing interest in automating this challenging task of lip reading. Indeed, automating the human ability to lip read, a process referred to as visual speech recognition (VSR) (or sometimes speech reading), could open the door for other novel related applications. VSR has received a great deal of attention in the last decade for its potential use in applications such as human-computer interaction (HCI), audio-visual speech recognition (AVSR), speaker recognition, talking heads, sign language recognition and video surveillance. Its main aim is to recognise spoken word(s) by using only the visual signal that is produced during speech. Hence, VSR deals with the visual domain of speech and involves image processing, artificial intelligence, object detection, pattern recognition, statistical modelling, etc.
Bypassing Captcha By Machine A Proof For Passing The Turing Test
Sep 03, 2014



For the last ten years, CAPTCHAs have been widely used by websites to prevent their data being automatically updated by machines. By supposedly allowing only humans to do so, CAPTCHAs take advantage of the reverse Turing test (TT), knowing that humans are more intelligent than machines. Generally, CAPTCHAs have defeated machines, but things are changing rapidly as technology improves. Hence, advanced research into optical character recognition (OCR) is overtaking attempts to strengthen CAPTCHAs against machine-based attacks. This paper investigates the immunity of CAPTCHA, which was built on the failure of the TT. We show that some CAPTCHAs are easily broken using a simple OCR machine built for the purpose of this study. By reviewing other techniques, we show that even more difficult CAPTCHAs can be broken using advanced OCR machines. Current advances in OCR should enable machines to pass the TT in the image recognition domain, which is exactly where machines are seeking to overcome CAPTCHAs. We enhance traditional CAPTCHAs by employing not only characters, but also natural language and multiple objects within the same CAPTCHA. The proposed CAPTCHAs might be able to hold out against machines, at least until the advent of a machine that passes the TT completely.