 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiabetic Retinopathy Detection using Ensemble Machine Learning
Jun 22, 2021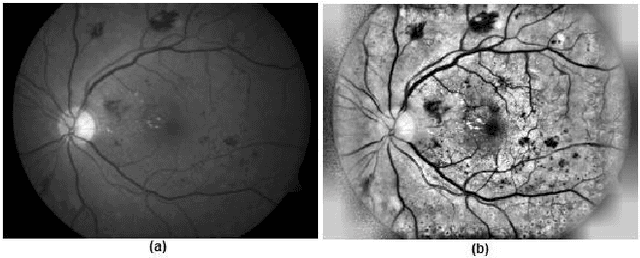
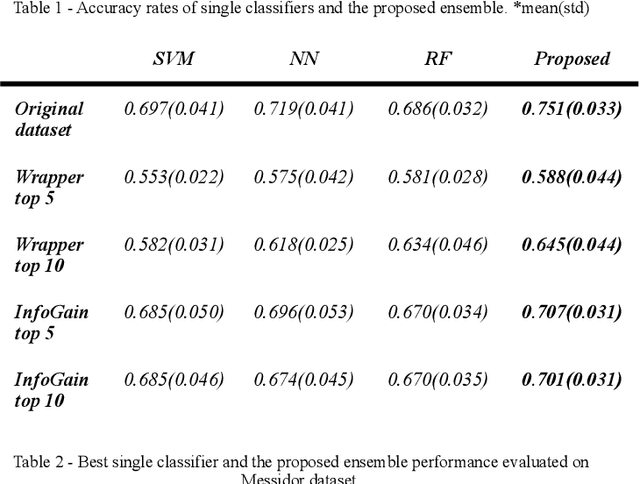
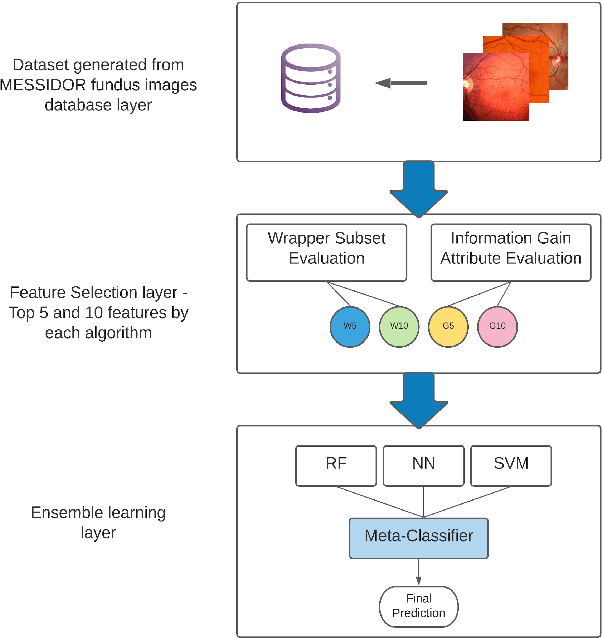
Diabetic Retinopathy (DR) is among the worlds leading vision loss causes in diabetic patients. DR is a microvascular disease that affects the eye retina, which causes vessel blockage and therefore cuts the main source of nutrition for the retina tissues. Treatment for this visual disorder is most effective when it is detected in its earliest stages, as severe DR can result in irreversible blindness. Nonetheless, DR identification requires the expertise of Ophthalmologists which is often expensive and time-consuming. Therefore, automatic detection systems were introduced aiming to facilitate the identification process, making it available globally in a time and cost-efficient manner. However, due to the limited reliable datasets and medical records for this particular eye disease, the obtained predictions accuracies were relatively unsatisfying for eye specialists to rely on them as diagnostic systems. Thus, we explored an ensemble-based learning strategy, merging a substantial selection of well-known classification algorithms in one sophisticated diagnostic model. The proposed framework achieved the highest accuracy rates among all other common classification algorithms in the area. 4 subdatasets were generated to contain the top 5 and top 10 features of the Messidor dataset, selected by InfoGainEval. and WrapperSubsetEval., accuracies of 70.7% and 75.1% were achieved on the InfoGainEval. top 5 and original dataset respectively. The results imply the impressive performance of the subdataset, which significantly conduces to a less complex classification process
Enhancing Genetic Algorithms using Multi Mutations
Jan 10, 2018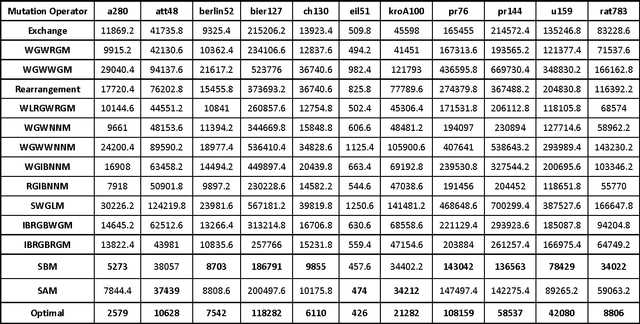
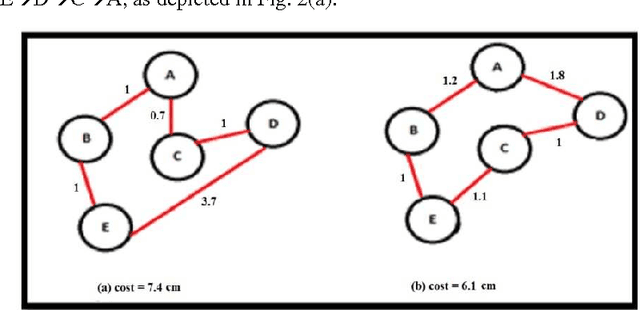
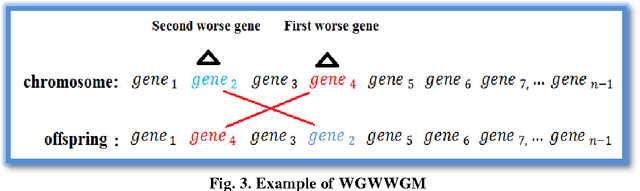
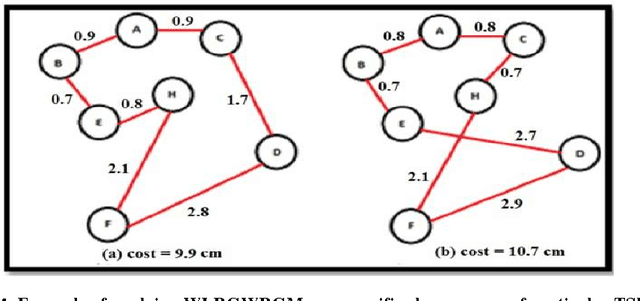
Mutation is one of the most important stages of the genetic algorithm because of its impact on the exploration of global optima, and to overcome premature convergence. There are many types of mutation, and the problem lies in selection of the appropriate type, where the decision becomes more difficult and needs more trial and error. This paper investigates the use of more than one mutation operator to enhance the performance of genetic algorithms. Novel mutation operators are proposed, in addition to two selection strategies for the mutation operators, one of which is based on selecting the best mutation operator and the other randomly selects any operator. Several experiments on some Travelling Salesman Problems (TSP) were conducted to evaluate the proposed methods, and these were compared to the well-known exchange mutation and rearrangement mutation. The results show the importance of some of the proposed methods, in addition to the significant enhancement of the genetic algorithm's performance, particularly when using more than one mutation operator.
* 17 pages, 11 figures, 1 table, 41 references
Evaluation of Machine Learning Algorithms for Intrusion Detection System
Jan 08, 2018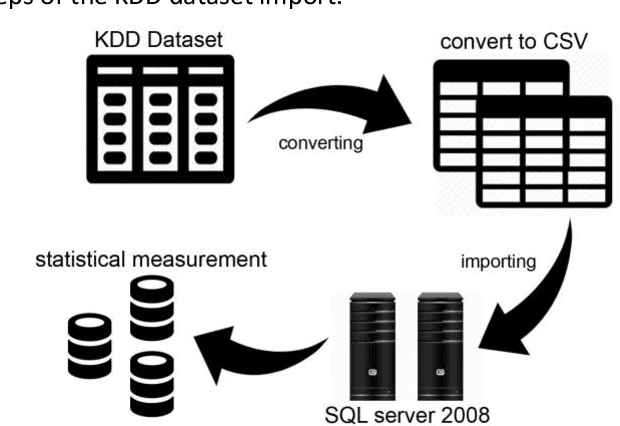
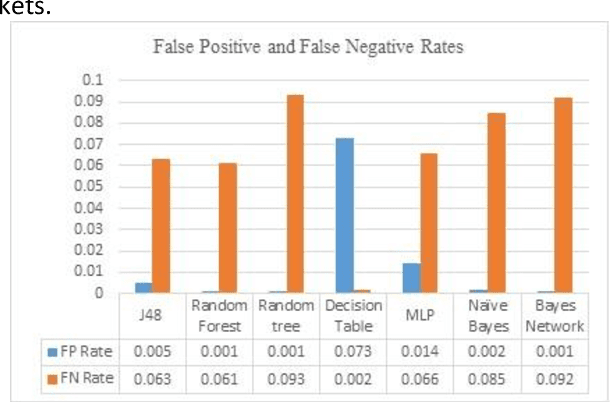
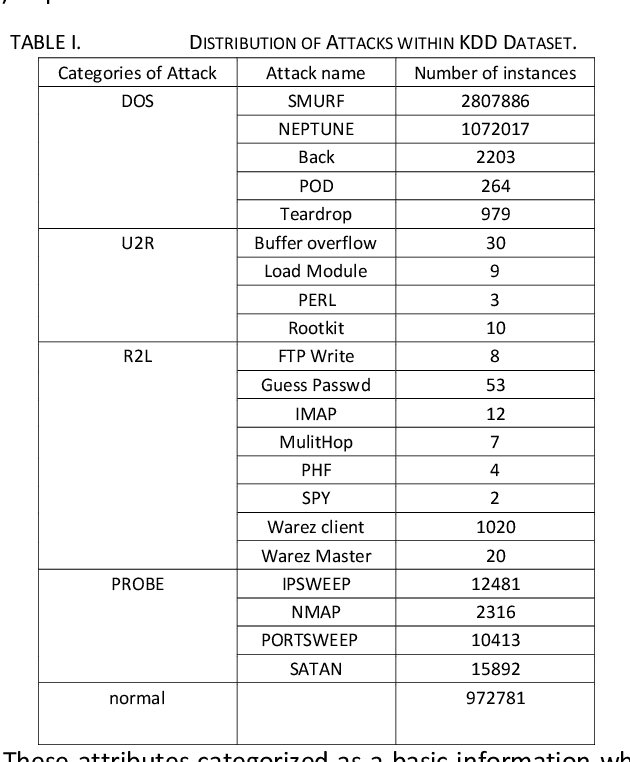
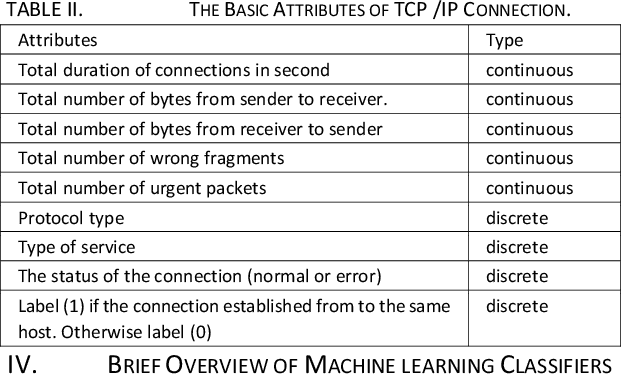
Intrusion detection system (IDS) is one of the implemented solutions against harmful attacks. Furthermore, attackers always keep changing their tools and techniques. However, implementing an accepted IDS system is also a challenging task. In this paper, several experiments have been performed and evaluated to assess various machine learning classifiers based on KDD intrusion dataset. It succeeded to compute several performance metrics in order to evaluate the selected classifiers. The focus was on false negative and false positive performance metrics in order to enhance the detection rate of the intrusion detection system. The implemented experiments demonstrated that the decision table classifier achieved the lowest value of false negative while the random forest classifier has achieved the highest average accuracy rate.
An empirical evaluation for the intrusion detection features based on machine learning and feature selection methods
Dec 27, 2017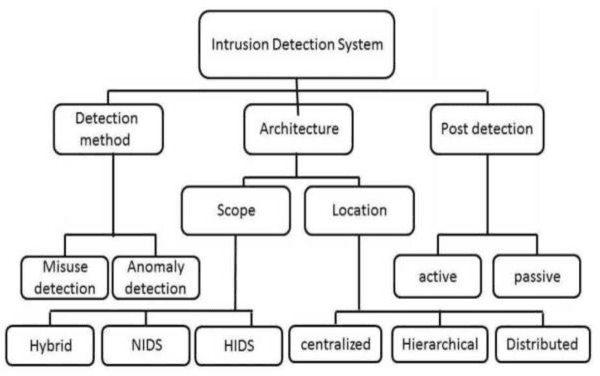
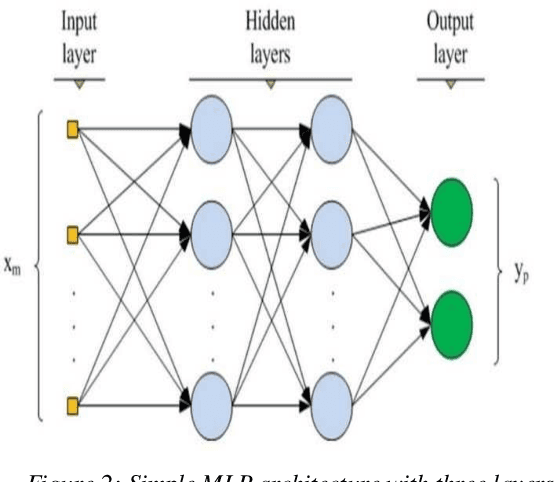
Despite the great developments in information technology, particularly the Internet, computer networks, global information exchange, and its positive impact in all areas of daily life, it has also contributed to the development of penetration and intrusion which forms a high risk to the security of information organizations, government agencies, and causes large economic losses. There are many techniques designed for protection such as firewall and intrusion detection systems (IDS). IDS is a set of software and/or hardware techniques used to detect hacker's activities in computer systems. Two types of anomalies are used in IDS to detect intrusive activities different from normal user behavior. Misuse relies on the knowledge base that contains all known attack techniques and intrusion is discovered through research in this knowledge base. Artificial intelligence techniques have been introduced to improve the performance of these systems. The importance of IDS is to identify unauthorized access attempting to compromise confidentiality, integrity or availability of the computer network. This paper investigates the Intrusion Detection (ID) problem using three machine learning algorithms namely, BayesNet algorithm, Multi-Layer Perceptron (MLP), and Support Vector Machine (SVM). The algorithms are applied on a real, Management Information Based (MIB) dataset that is collected from real life environment. To enhance the detection process accuracy, a set of feature selection approaches is used; Infogain (IG), ReleifF (RF), and Genetic Search (GS). Our experiments show that the three feature selection methods have enhanced the classification performance. GS with bayesNet, MLP and SVM give high accuracy rates, more specifically the BayesNet with the GS accuracy rate is 99.9%.
On Enhancing The Performance Of Nearest Neighbour Classifiers Using Hassanat Distance Metric
Jan 04, 2015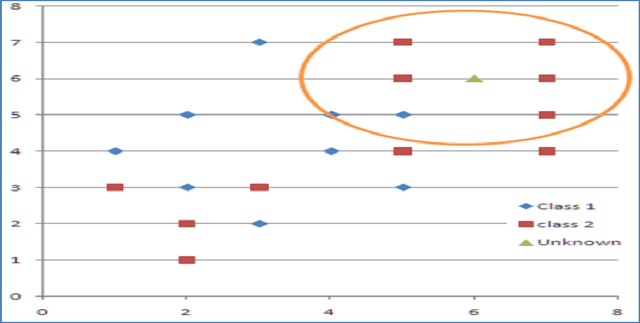
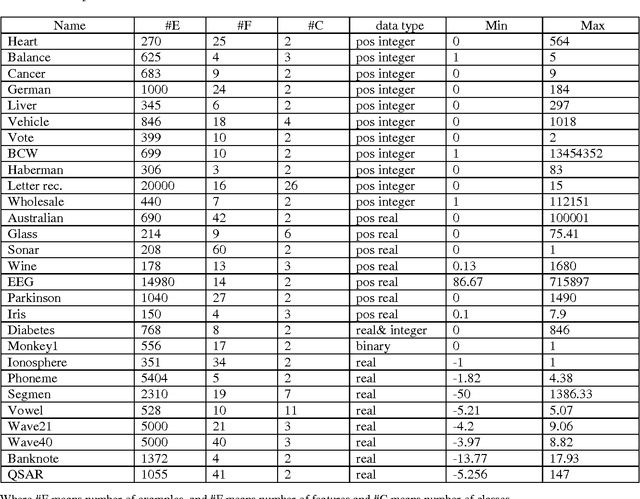
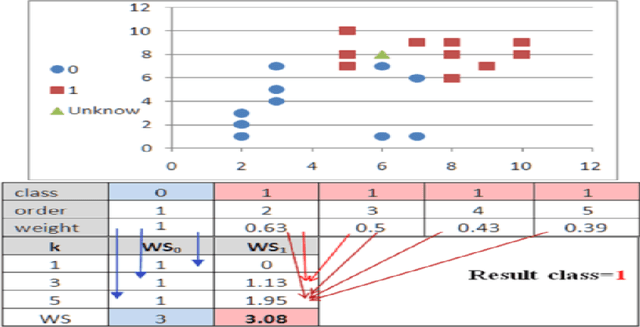
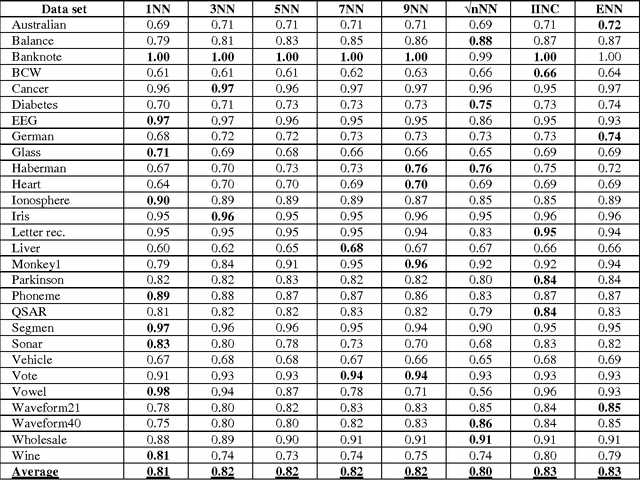
We showed in this work how the Hassanat distance metric enhances the performance of the nearest neighbour classifiers. The results demonstrate the superiority of this distance metric over the traditional and most-used distances, such as Manhattan distance and Euclidian distance. Moreover, we proved that the Hassanat distance metric is invariant to data scale, noise and outliers. Throughout this work, it is clearly notable that both ENN and IINC performed very well with the distance investigated, as their accuracy increased significantly by 3.3% and 3.1% respectively, with no significant advantage of the ENN over the IINC in terms of accuracy. Correspondingly, it can be noted from our results that there is no optimal algorithm that can solve all real-life problems perfectly; this is supported by the no-free-lunch theorem