 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Oversampling for Class Imbalance Learning: A Critical Review
Feb 04, 2022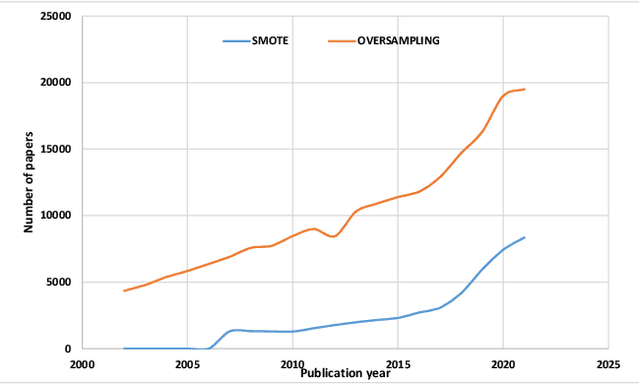
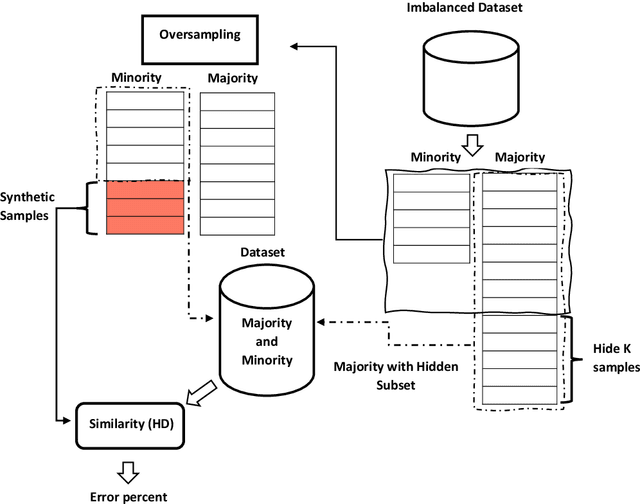

For the last two decades, oversampling has been employed to overcome the challenge of learning from imbalanced datasets. Many approaches to solving this challenge have been offered in the literature. Oversampling, on the other hand, is a concern. That is, models trained on fictitious data may fail spectacularly when put to real-world problems. The fundamental difficulty with oversampling approaches is that, given a real-life population, the synthesized samples may not truly belong to the minority class. As a result, training a classifier on these samples while pretending they represent minority may result in incorrect predictions when the model is used in the real world. We analyzed a large number of oversampling methods in this paper and devised a new oversampling evaluation system based on hiding a number of majority examples and comparing them to those generated by the oversampling process. Based on our evaluation system, we ranked all these methods based on their incorrectly generated examples for comparison. Our experiments using more than 70 oversampling methods and three imbalanced real-world datasets reveal that all oversampling methods studied generate minority samples that are most likely to be majority. Given data and methods in hand, we argue that oversampling in its current forms and methodologies is unreliable for learning from class imbalanced data and should be avoided in real-world applications.
Fuzzy Win-Win: A Novel Approach to Quantify Win-Win Using Fuzzy Logic
Dec 13, 2021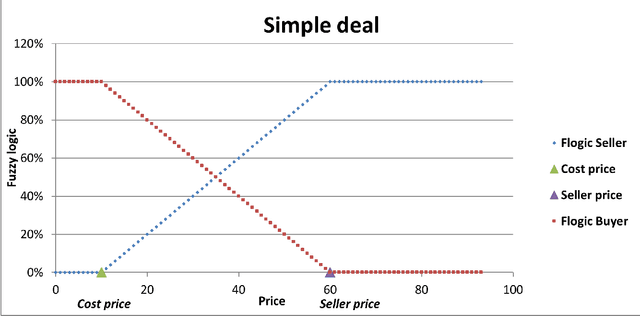
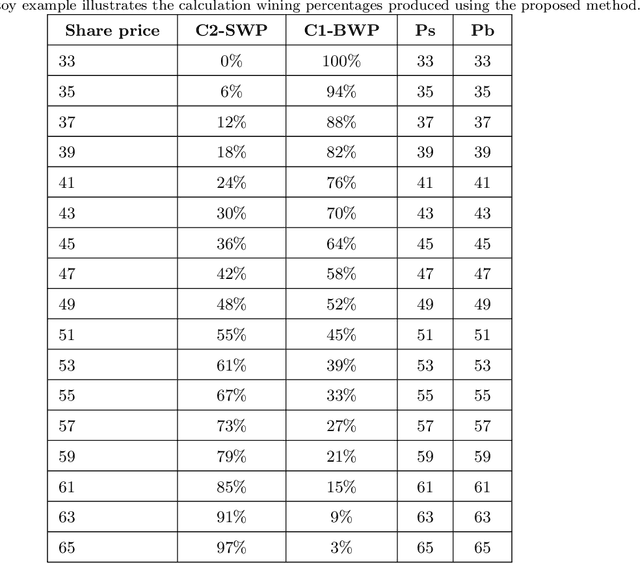
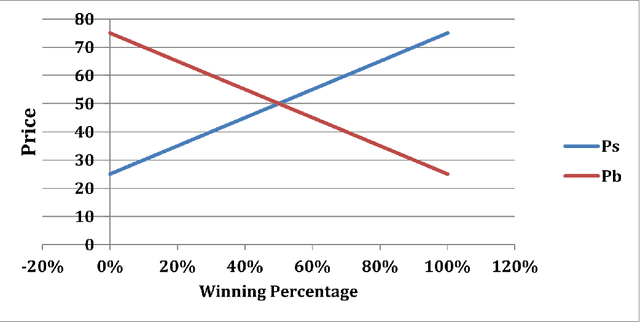
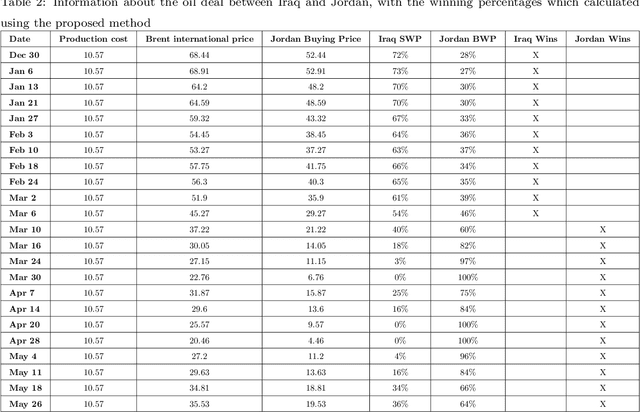
The classic win-win has a key flaw in that it cannot offer the parties the right amounts of winning because each party believes they are winners. In reality, one party may win more than the other. This strategy is not limited to a single product or negotiation; it may be applied to a variety of situations in life. We present a novel way to measure the win-win situation in this paper. The proposed method employs Fuzzy logic to create a mathematical model that aids negotiators in quantifying their winning percentages. The model is put to the test on real-life negotiations scenarios such as the Iranian uranium enrichment negotiations, the Iraqi-Jordanian oil deal, and the iron ore negotiation (2005-2009). The presented model has shown to be a useful tool in practice and can be easily generalized to be utilized in other domains as well.
On Enhancing The Performance Of Nearest Neighbour Classifiers Using Hassanat Distance Metric
Jan 04, 2015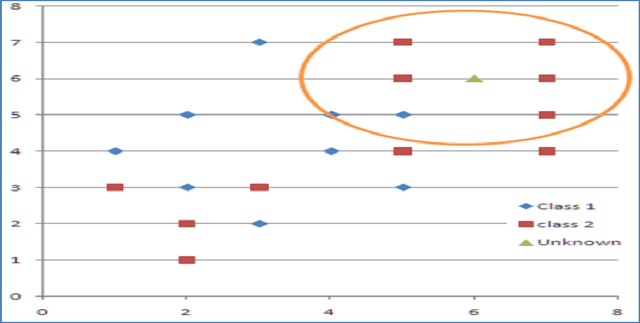
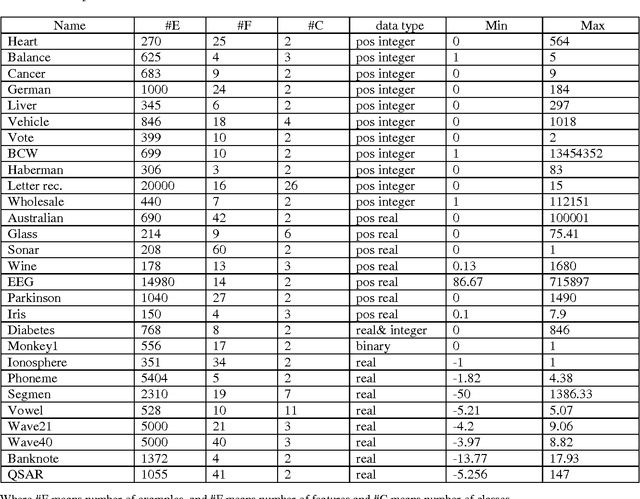
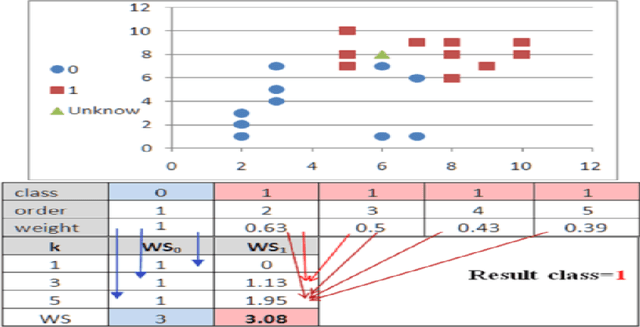
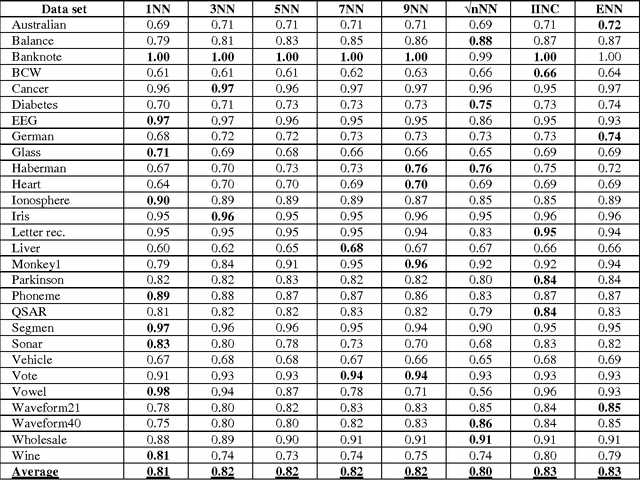
We showed in this work how the Hassanat distance metric enhances the performance of the nearest neighbour classifiers. The results demonstrate the superiority of this distance metric over the traditional and most-used distances, such as Manhattan distance and Euclidian distance. Moreover, we proved that the Hassanat distance metric is invariant to data scale, noise and outliers. Throughout this work, it is clearly notable that both ENN and IINC performed very well with the distance investigated, as their accuracy increased significantly by 3.3% and 3.1% respectively, with no significant advantage of the ENN over the IINC in terms of accuracy. Correspondingly, it can be noted from our results that there is no optimal algorithm that can solve all real-life problems perfectly; this is supported by the no-free-lunch theorem