 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Oversampling for Class Imbalance Learning: A Critical Review
Paper and Code
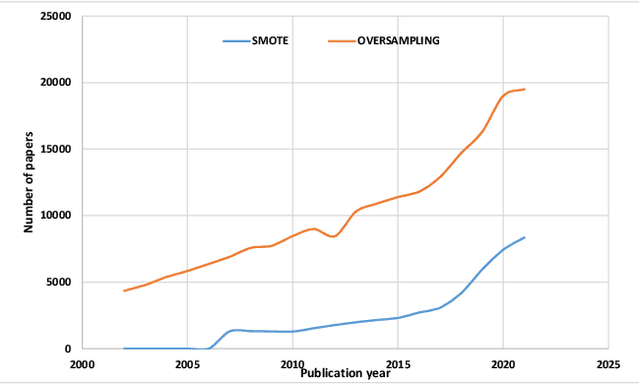
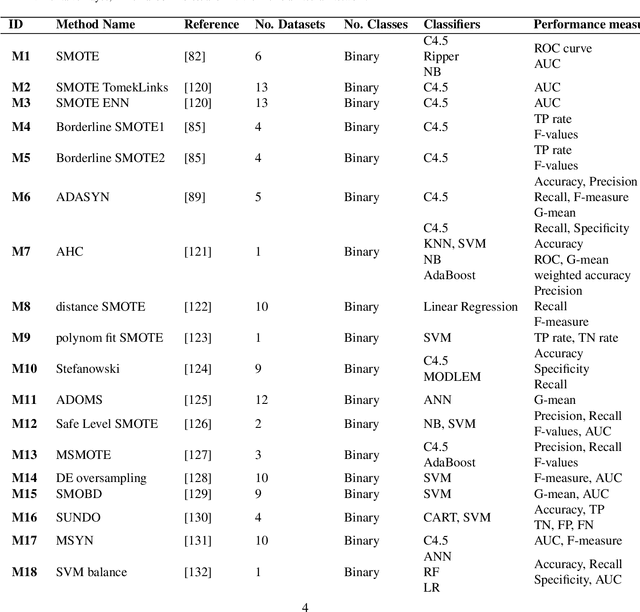
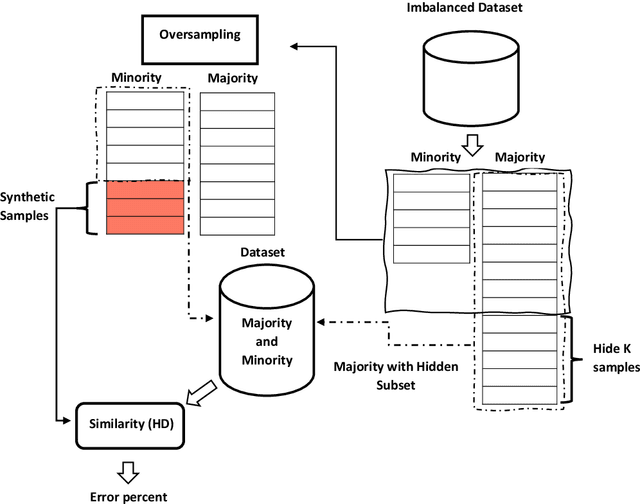

For the last two decades, oversampling has been employed to overcome the challenge of learning from imbalanced datasets. Many approaches to solving this challenge have been offered in the literature. Oversampling, on the other hand, is a concern. That is, models trained on fictitious data may fail spectacularly when put to real-world problems. The fundamental difficulty with oversampling approaches is that, given a real-life population, the synthesized samples may not truly belong to the minority class. As a result, training a classifier on these samples while pretending they represent minority may result in incorrect predictions when the model is used in the real world. We analyzed a large number of oversampling methods in this paper and devised a new oversampling evaluation system based on hiding a number of majority examples and comparing them to those generated by the oversampling process. Based on our evaluation system, we ranked all these methods based on their incorrectly generated examples for comparison. Our experiments using more than 70 oversampling methods and three imbalanced real-world datasets reveal that all oversampling methods studied generate minority samples that are most likely to be majority. Given data and methods in hand, we argue that oversampling in its current forms and methodologies is unreliable for learning from class imbalanced data and should be avoided in real-world applications.