 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Oversampling for Class Imbalance Learning: A Critical Review
Feb 04, 2022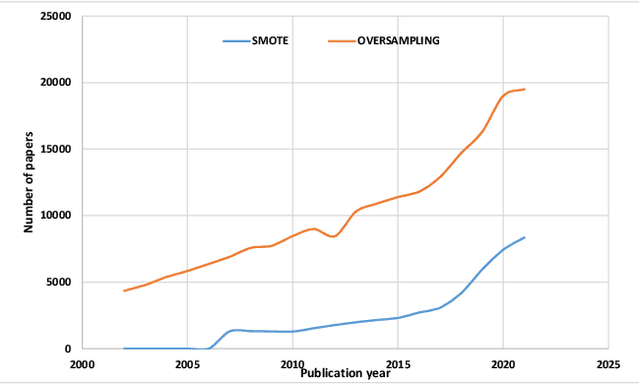
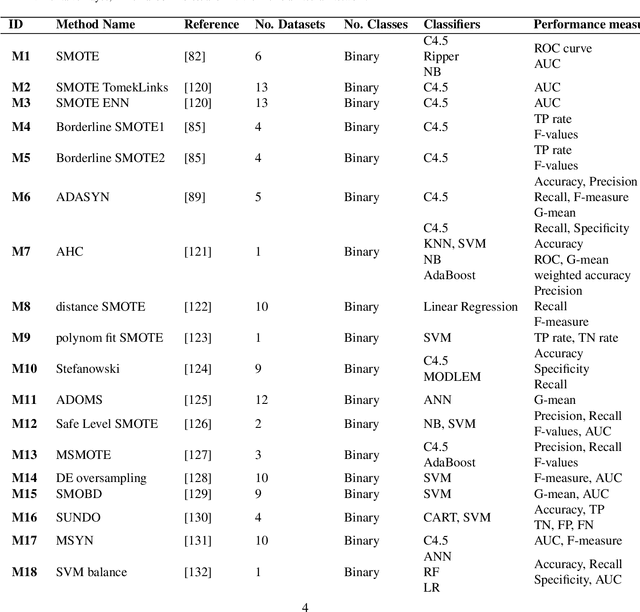
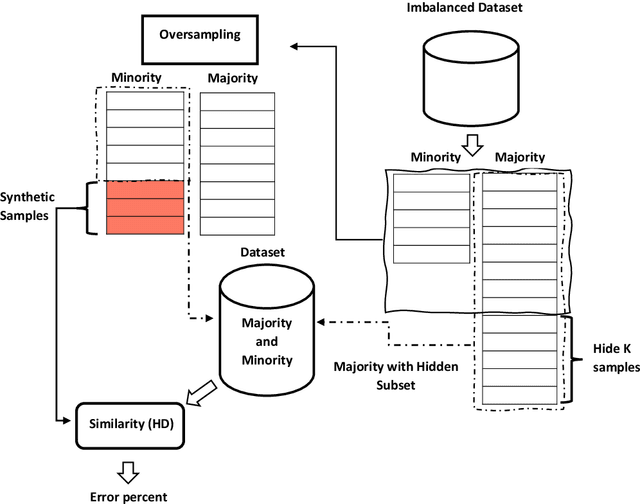

For the last two decades, oversampling has been employed to overcome the challenge of learning from imbalanced datasets. Many approaches to solving this challenge have been offered in the literature. Oversampling, on the other hand, is a concern. That is, models trained on fictitious data may fail spectacularly when put to real-world problems. The fundamental difficulty with oversampling approaches is that, given a real-life population, the synthesized samples may not truly belong to the minority class. As a result, training a classifier on these samples while pretending they represent minority may result in incorrect predictions when the model is used in the real world. We analyzed a large number of oversampling methods in this paper and devised a new oversampling evaluation system based on hiding a number of majority examples and comparing them to those generated by the oversampling process. Based on our evaluation system, we ranked all these methods based on their incorrectly generated examples for comparison. Our experiments using more than 70 oversampling methods and three imbalanced real-world datasets reveal that all oversampling methods studied generate minority samples that are most likely to be majority. Given data and methods in hand, we argue that oversampling in its current forms and methodologies is unreliable for learning from class imbalanced data and should be avoided in real-world applications.
Fuzzy Win-Win: A Novel Approach to Quantify Win-Win Using Fuzzy Logic
Dec 13, 2021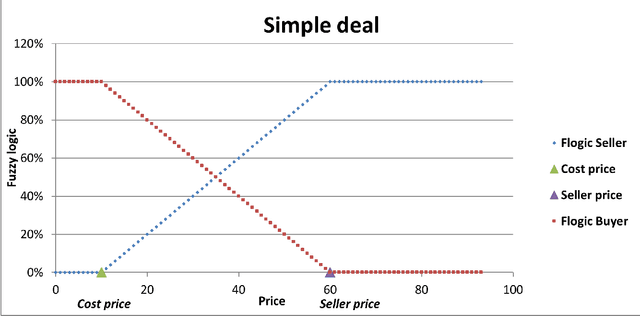
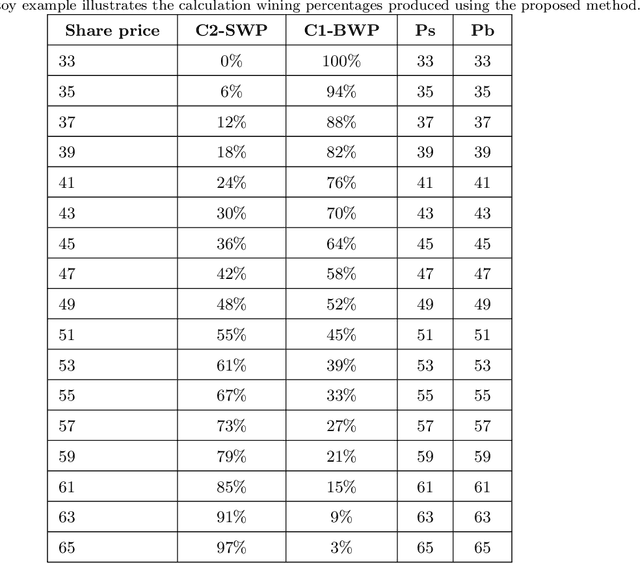
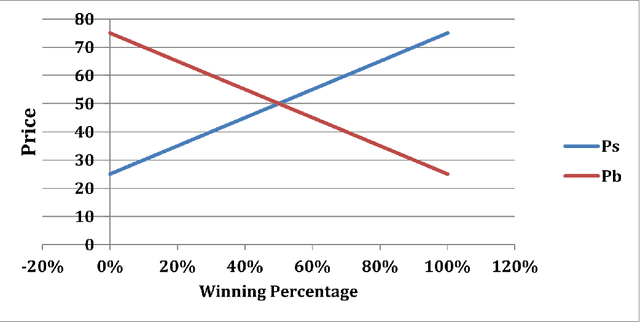
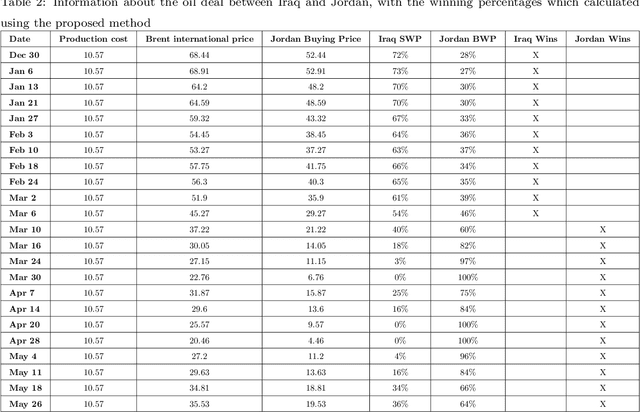
The classic win-win has a key flaw in that it cannot offer the parties the right amounts of winning because each party believes they are winners. In reality, one party may win more than the other. This strategy is not limited to a single product or negotiation; it may be applied to a variety of situations in life. We present a novel way to measure the win-win situation in this paper. The proposed method employs Fuzzy logic to create a mathematical model that aids negotiators in quantifying their winning percentages. The model is put to the test on real-life negotiations scenarios such as the Iranian uranium enrichment negotiations, the Iraqi-Jordanian oil deal, and the iron ore negotiation (2005-2009). The presented model has shown to be a useful tool in practice and can be easily generalized to be utilized in other domains as well.
Deep learning for identification and face, gender, expression recognition under constraints
Nov 02, 2021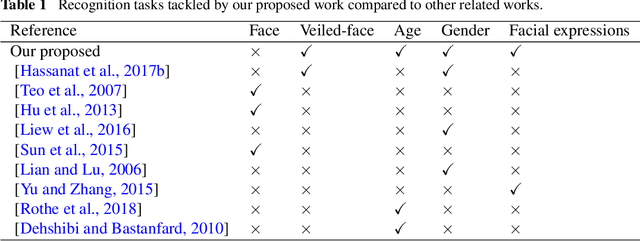

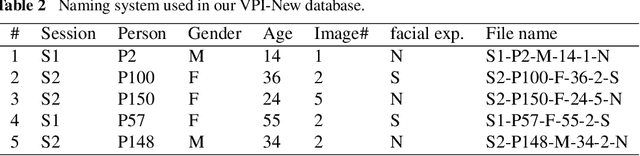
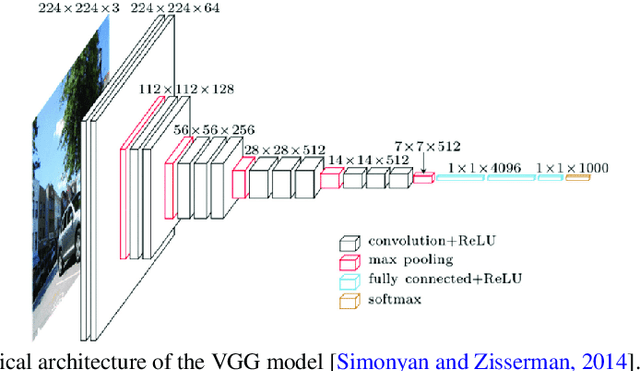
Biometric recognition based on the full face is an extensive research area. However, using only partially visible faces, such as in the case of veiled-persons, is a challenging task. Deep convolutional neural network (CNN) is used in this work to extract the features from veiled-person face images. We found that the sixth and the seventh fully connected layers, FC6 and FC7 respectively, in the structure of the VGG19 network provide robust features with each of these two layers containing 4096 features. The main objective of this work is to test the ability of deep learning based automated computer system to identify not only persons, but also to perform recognition of gender, age, and facial expressions such as eye smile. Our experimental results indicate that we obtain high accuracy for all the tasks. The best recorded accuracy values are up to 99.95% for identifying persons, 99.9% for gender recognition, 99.9% for age recognition and 80.9% for facial expression (eye smile) recognition.
Detailed Investigation of Deep Features with Sparse Representation and Dimensionality Reduction in CBIR: A Comparative Study
Nov 23, 2018
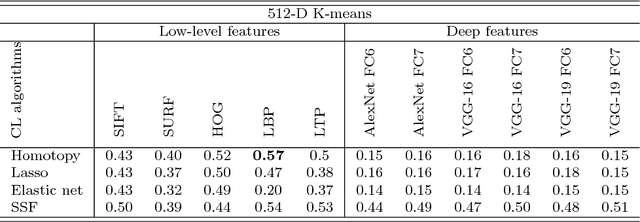

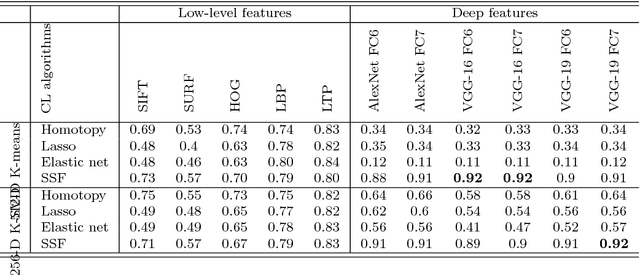
Research on content-based image retrieval (CBIR) has been under development for decades, and numerous methods have been competing to extract the most discriminative features for improved representation of the image content. Recently, deep learning methods have gained attention in computer vision, including CBIR. In this paper, we present a comparative investigation of different features, including low-level and high-level features, for CBIR. We compare the performance of CBIR systems using different deep features with state-of-the-art low-level features such as SIFT, SURF, HOG, LBP, and LTP, using different dictionaries and coefficient learning techniques. Furthermore, we conduct comparisons with a set of primitive and popular features that have been used in this field, including colour histograms and Gabor features. We also investigate the discriminative power of deep features using certain similarity measures under different validation approaches. Furthermore, we investigate the effects of the dimensionality reduction of deep features on the performance of CBIR systems using principal component analysis, discrete wavelet transform, and discrete cosine transform. Unprecedentedly, the experimental results demonstrate high (95\% and 93\%) mean average precisions when using the VGG-16 FC7 deep features of Corel-1000 and Coil-20 datasets with 10-D and 20-D K-SVD, respectively.
Greedy Algorithms for Approximating the Diameter of Machine Learning Datasets in Multidimensional Euclidean Space
Aug 10, 2018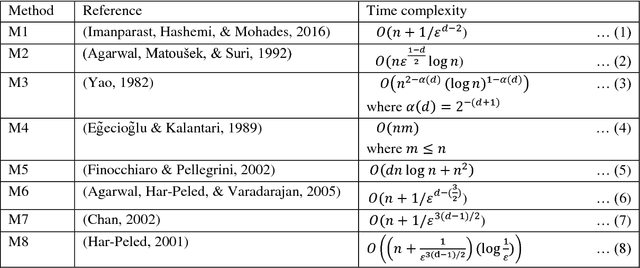
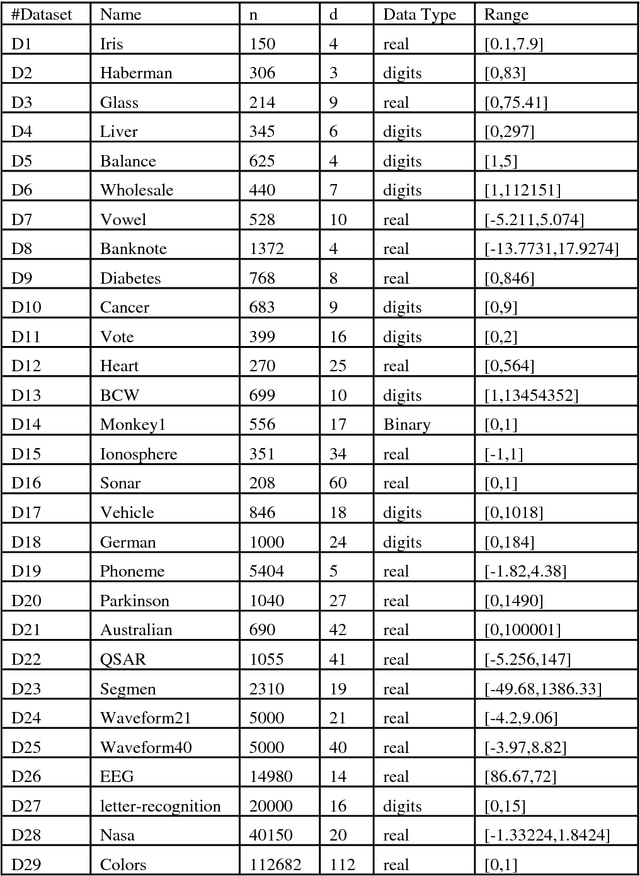
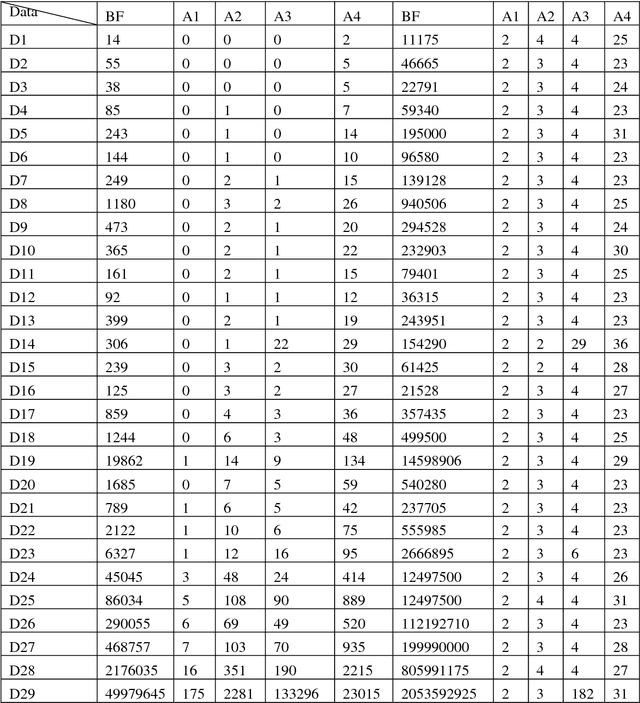
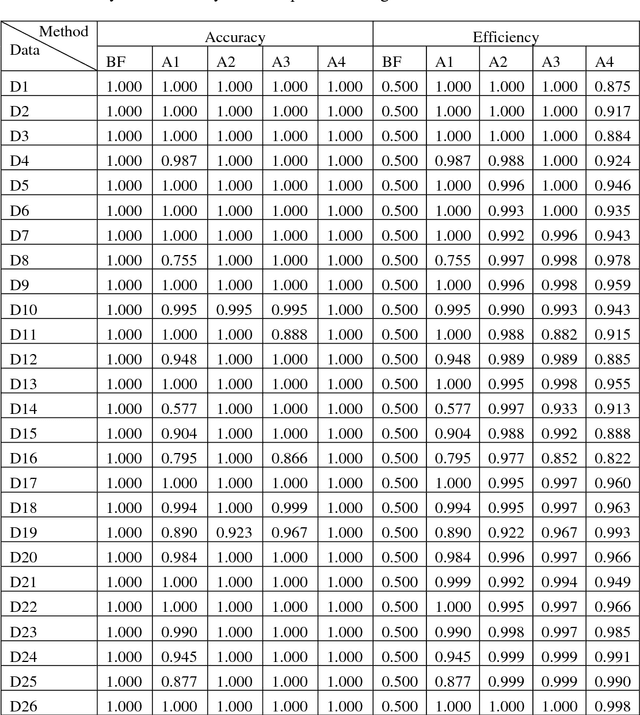
Finding the diameter of a dataset in multidimensional Euclidean space is a well-established problem, with well-known algorithms. However, most of the algorithms found in the literature do not scale well with large values of data dimension, so the time complexity grows exponentially in most cases, which makes these algorithms impractical. Therefore, we implemented 4 simple greedy algorithms to be used for approximating the diameter of a multidimensional dataset; these are based on minimum/maximum l2 norms, hill climbing search, Tabu search and Beam search approaches, respectively. The time complexity of the implemented algorithms is near-linear, as they scale near-linearly with data size and its dimensions. The results of the experiments (conducted on different machine learning data sets) prove the efficiency of the implemented algorithms and can therefore be recommended for finding the diameter to be used by different machine learning applications when needed.