 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Algorithms for Approximating the Diameter of Machine Learning Datasets in Multidimensional Euclidean Space
Paper and Code
Aug 10, 2018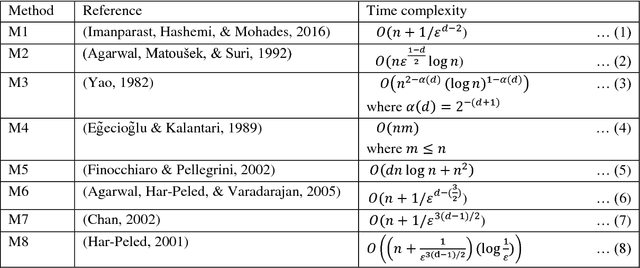
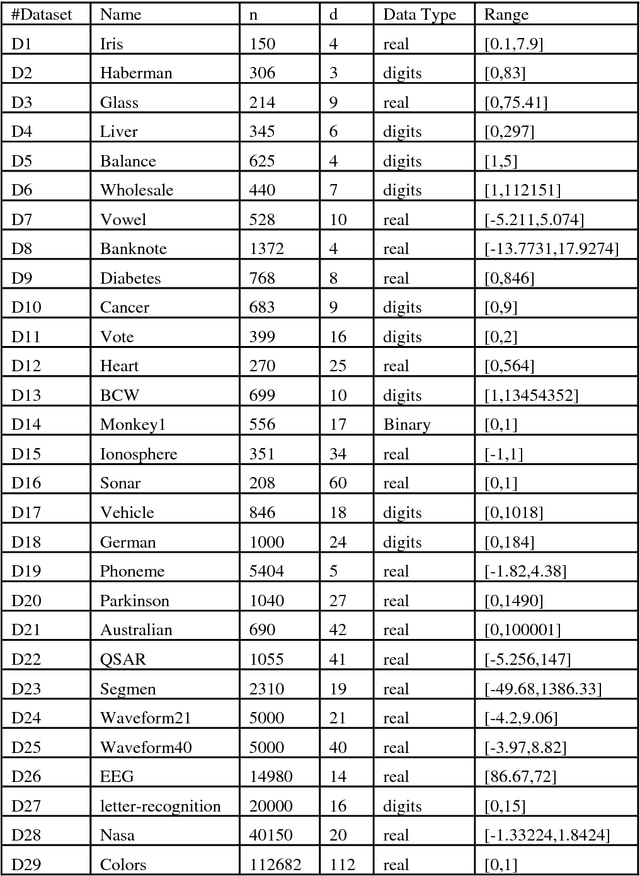
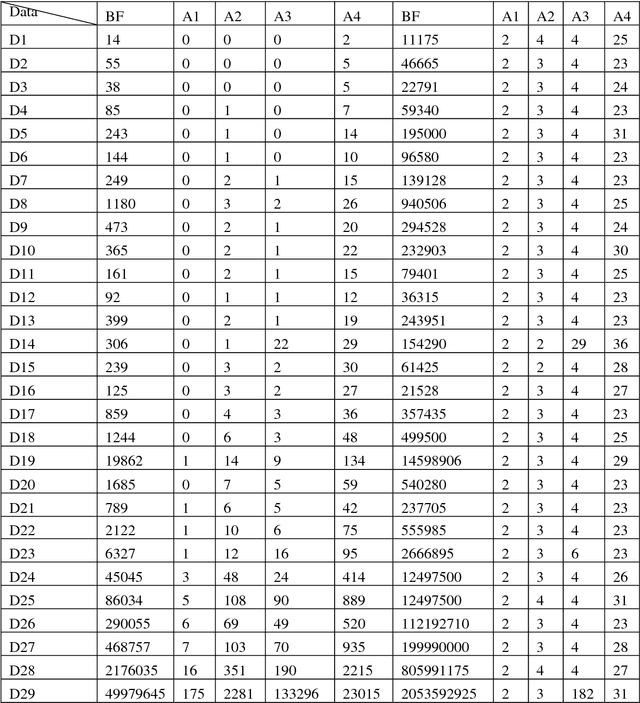
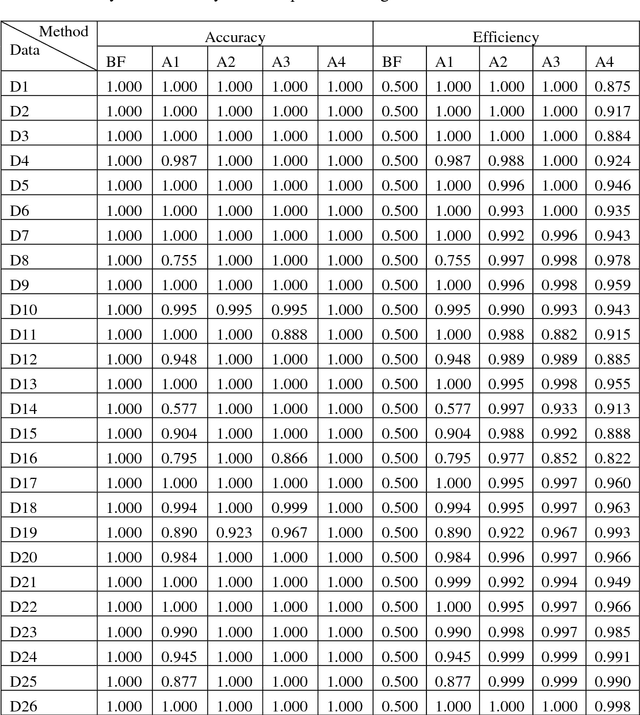
Finding the diameter of a dataset in multidimensional Euclidean space is a well-established problem, with well-known algorithms. However, most of the algorithms found in the literature do not scale well with large values of data dimension, so the time complexity grows exponentially in most cases, which makes these algorithms impractical. Therefore, we implemented 4 simple greedy algorithms to be used for approximating the diameter of a multidimensional dataset; these are based on minimum/maximum l2 norms, hill climbing search, Tabu search and Beam search approaches, respectively. The time complexity of the implemented algorithms is near-linear, as they scale near-linearly with data size and its dimensions. The results of the experiments (conducted on different machine learning data sets) prove the efficiency of the implemented algorithms and can therefore be recommended for finding the diameter to be used by different machine learning applications when needed.