 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-and Dictionary-based Solution for Variations in Written Arabic Names in Social Networks, Big Data, Accounting Systems and Large Databases
Feb 18, 2015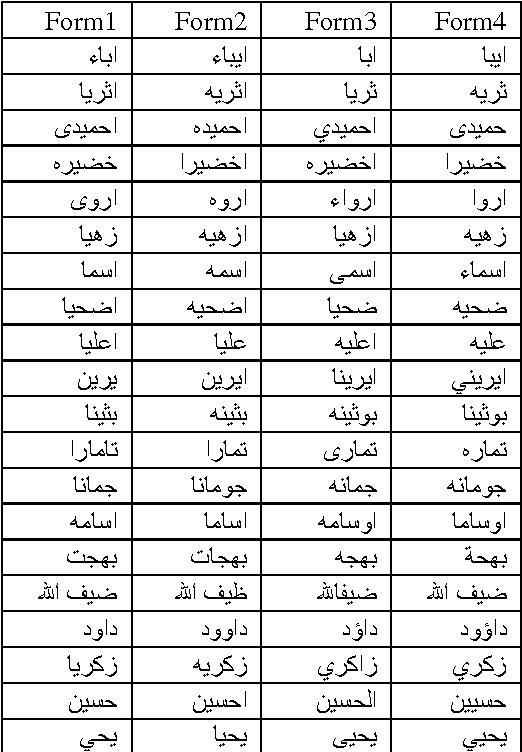
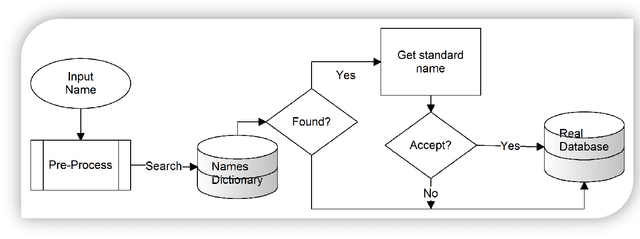
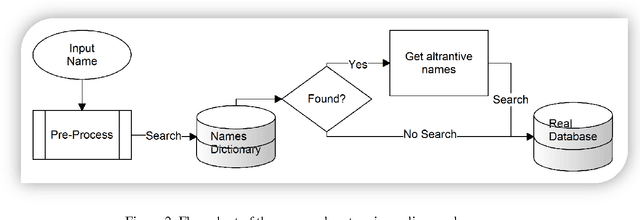
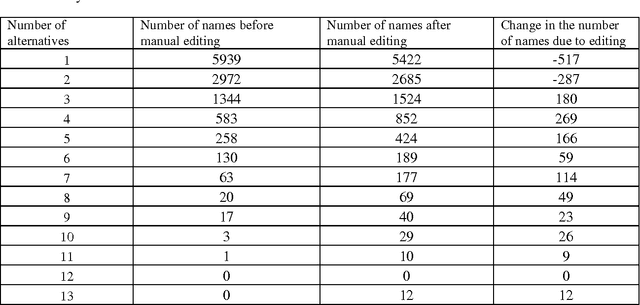
This paper investigates the problem that some Arabic names can be written in multiple ways. When someone searches for only one form of a name, neither exact nor approximate matching is appropriate for returning the multiple variants of the name. Exact matching requires the user to enter all forms of the name for the search, and approximate matching yields names not among the variations of the one being sought. In this paper, we attempt to solve the problem with a dictionary of all Arabic names mapped to their different (alternative) writing forms. We generated alternatives based on rules we derived from reviewing the first names of 9.9 million citizens and former citizens of Jordan. This dictionary can be used for both standardizing the written form when inserting a new name into a database and for searching for the name and all its alternative written forms. Creating the dictionary automatically based on rules resulted in at least 7% erroneous acceptance errors and 7.9% erroneous rejection errors. We addressed the errors by manually editing the dictionary. The dictionary can be of help to real world-databases, with the qualification that manual editing does not guarantee 100% correctness.
Solving the Problem of the K Parameter in the KNN Classifier Using an Ensemble Learning Approach
Sep 02, 2014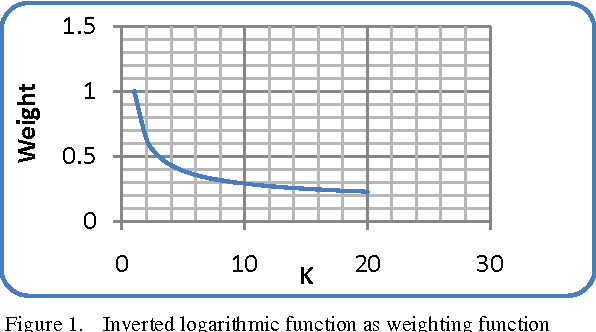
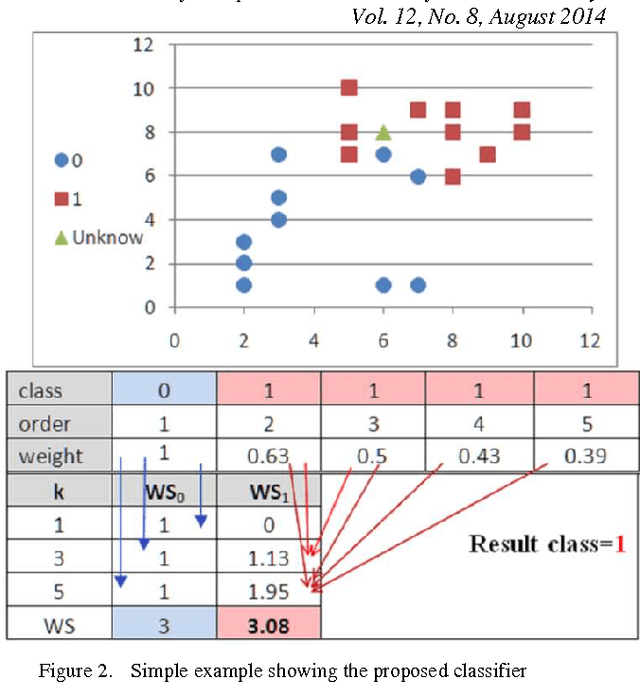
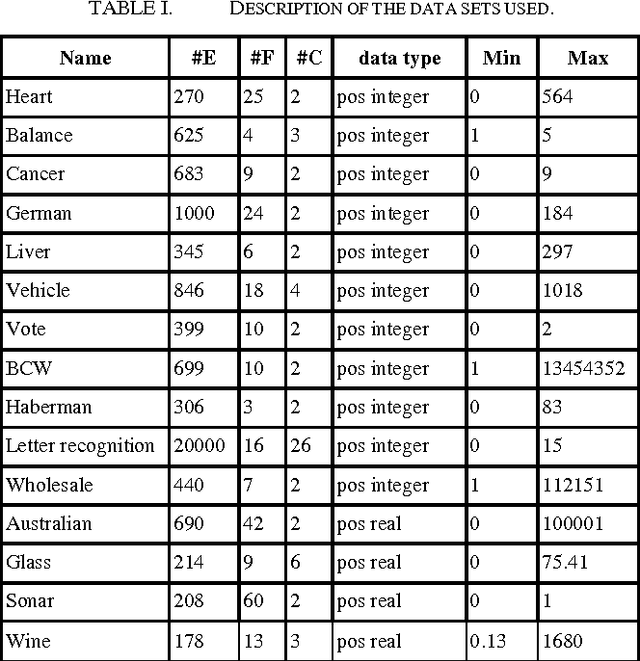
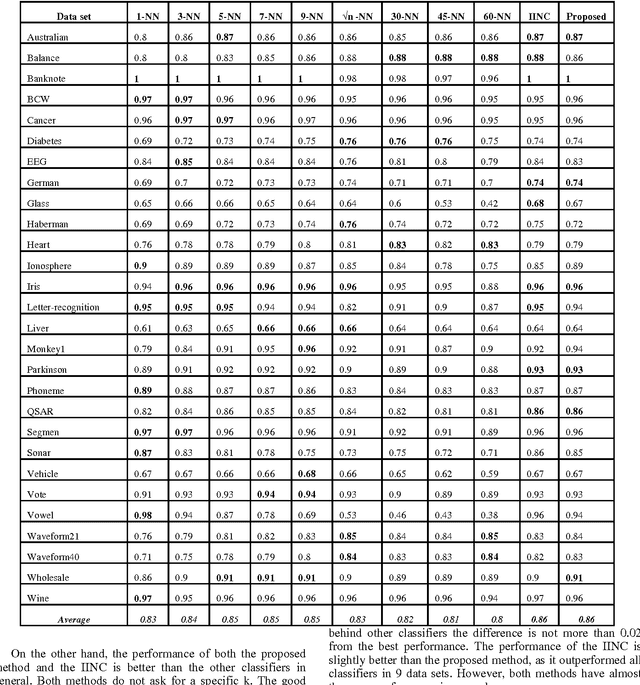
This paper presents a new solution for choosing the K parameter in the k-nearest neighbor (KNN) algorithm, the solution depending on the idea of ensemble learning, in which a weak KNN classifier is used each time with a different K, starting from one to the square root of the size of the training set. The results of the weak classifiers are combined using the weighted sum rule. The proposed solution was tested and compared to other solutions using a group of experiments in real life problems. The experimental results show that the proposed classifier outperforms the traditional KNN classifier that uses a different number of neighbors, is competitive with other classifiers, and is a promising classifier with strong potential for a wide range of applications.