 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance and Similarity Measures Effect on the Performance of K-Nearest Neighbor Classifier - A Review
Paper and Code
Aug 14, 2017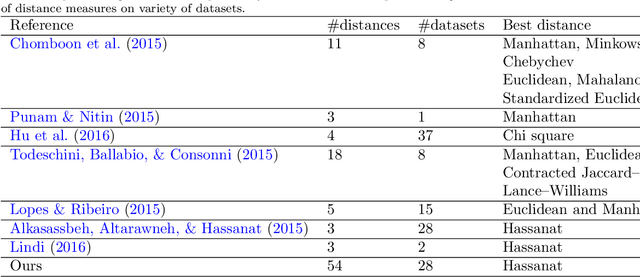



The K-nearest neighbor (KNN) classifier is one of the simplest and most common classifiers, yet its performance competes with the most complex classifiers in the literature. The core of this classifier depends mainly on measuring the distance or similarity between the tested example and the training examples. This raises a major question about which distance measures to be used for the KNN classifier among a large number of distance and similarity measures? This review attempts to answer the previous question through evaluating the performance (measured by accuracy, precision and recall) of the KNN using a large number of distance measures, tested on a number of real world datasets, with and without adding different levels of noise. The experimental results show that the performance of KNN classifier depends significantly on the distance used, the results showed large gaps between the performances of different distances. We found that a recently proposed non-convex distance performed the best when applied on most datasets comparing to the other tested distances. In addition, the performance of the KNN degraded only about $20\%$ while the noise level reaches $90\%$, this is true for all the distances used. This means that the KNN classifier using any of the top $10$ distances tolerate noise to a certain degree. Moreover, the results show that some distances are less affected by the added noise comparing to other distances.