 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL$^3$: Boosting Meta Reinforcement Learning via RL inside RL$^2$
Jun 28, 2023



Meta reinforcement learning (meta-RL) methods such as RL$^2$ have emerged as promising approaches for learning data-efficient RL algorithms tailored to a given task distribution. However, these RL algorithms struggle with long-horizon tasks and out-of-distribution tasks since they rely on recurrent neural networks to process the sequence of experiences instead of summarizing them into general RL components such as value functions. Moreover, even transformers have a practical limit to the length of histories they can efficiently reason about before training and inference costs become prohibitive. In contrast, traditional RL algorithms are data-inefficient since they do not leverage domain knowledge, but they do converge to an optimal policy as more data becomes available. In this paper, we propose RL$^3$, a principled hybrid approach that combines traditional RL and meta-RL by incorporating task-specific action-values learned through traditional RL as an input to the meta-RL neural network. We show that RL$^3$ earns greater cumulative reward on long-horizon and out-of-distribution tasks compared to RL$^2$, while maintaining the efficiency of the latter in the short term. Experiments are conducted on both custom and benchmark discrete domains from the meta-RL literature that exhibit a range of short-term, long-term, and complex dependencies.
Adaptive Rollout Length for Model-Based RL Using Model-Free Deep RL
Jun 07, 2022
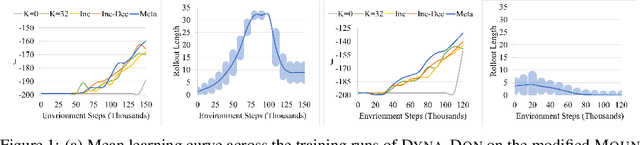
Model-based reinforcement learning promises to learn an optimal policy from fewer interactions with the environment compared to model-free reinforcement learning by learning an intermediate model of the environment in order to predict future interactions. When predicting a sequence of interactions, the rollout length, which limits the prediction horizon, is a critical hyperparameter as accuracy of the predictions diminishes in the regions that are further away from real experience. As a result, with a longer rollout length, an overall worse policy is learned in the long run. Thus, the hyperparameter provides a trade-off between quality and efficiency. In this work, we frame the problem of tuning the rollout length as a meta-level sequential decision-making problem that optimizes the final policy learned by model-based reinforcement learning given a fixed budget of environment interactions by adapting the hyperparameter dynamically based on feedback from the learning process, such as accuracy of the model and the remaining budget of interactions. We use model-free deep reinforcement learning to solve the meta-level decision problem and demonstrate that our approach outperforms common heuristic baselines on two well-known reinforcement learning environments.
Resource Constrained Deep Reinforcement Learning
Dec 03, 2018



In urban environments, supply resources have to be constantly matched to the "right" locations (where customer demand is present) so as to improve quality of life. For instance, ambulances have to be matched to base stations regularly so as to reduce response time for emergency incidents in EMS (Emergency Management Systems); vehicles (cars, bikes, scooters etc.) have to be matched to docking stations so as to reduce lost demand in shared mobility systems. Such problem domains are challenging owing to the demand uncertainty, combinatorial action spaces (due to allocation) and constraints on allocation of resources (e.g., total resources, minimum and maximum number of resources at locations and regions). Existing systems typically employ myopic and greedy optimization approaches to optimize allocation of supply resources to locations. Such approaches typically are unable to handle surges or variances in demand patterns well. Recent research has demonstrated the ability of Deep RL methods in adapting well to highly uncertain environments. However, existing Deep RL methods are unable to handle combinatorial action spaces and constraints on allocation of resources. To that end, we have developed three approaches on top of the well known actor critic approach, DDPG (Deep Deterministic Policy Gradient) that are able to handle constraints on resource allocation. More importantly, we demonstrate that they are able to outperform leading approaches on simulators validated on semi-real and real data sets.