 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Rollout Length for Model-Based RL Using Model-Free Deep RL
Paper and Code
Jun 07, 2022
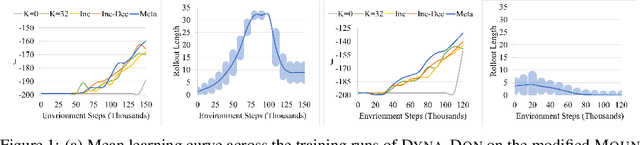
Model-based reinforcement learning promises to learn an optimal policy from fewer interactions with the environment compared to model-free reinforcement learning by learning an intermediate model of the environment in order to predict future interactions. When predicting a sequence of interactions, the rollout length, which limits the prediction horizon, is a critical hyperparameter as accuracy of the predictions diminishes in the regions that are further away from real experience. As a result, with a longer rollout length, an overall worse policy is learned in the long run. Thus, the hyperparameter provides a trade-off between quality and efficiency. In this work, we frame the problem of tuning the rollout length as a meta-level sequential decision-making problem that optimizes the final policy learned by model-based reinforcement learning given a fixed budget of environment interactions by adapting the hyperparameter dynamically based on feedback from the learning process, such as accuracy of the model and the remaining budget of interactions. We use model-free deep reinforcement learning to solve the meta-level decision problem and demonstrate that our approach outperforms common heuristic baselines on two well-known reinforcement learning environments.