 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning by Reconstructing Neighborhoods
Nov 06, 2018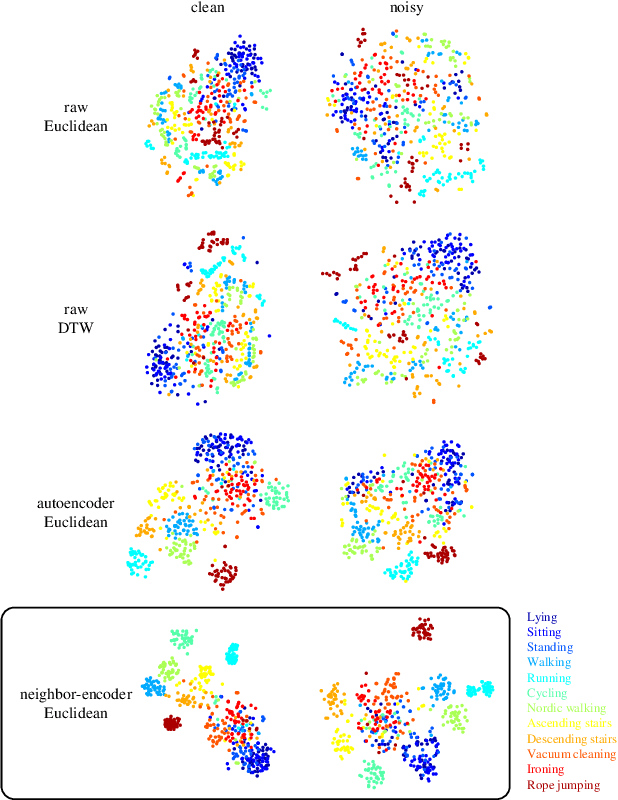
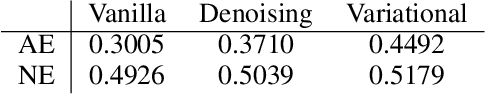
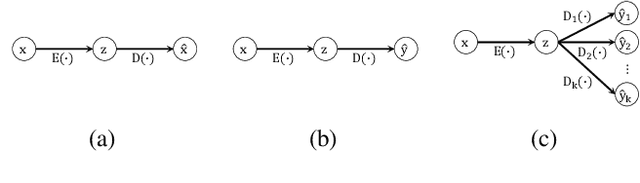
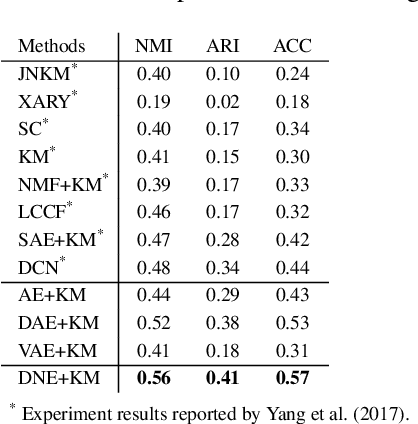
Since its introduction, unsupervised representation learning has attracted a lot of attention from the research community, as it is demonstrated to be highly effective and easy-to-apply in tasks such as dimension reduction, clustering, visualization, information retrieval, and semi-supervised learning. In this work, we propose a novel unsupervised representation learning framework called neighbor-encoder, in which domain knowledge can be easily incorporated into the learning process without modifying the general encoder-decoder architecture of the classic autoencoder.In contrast to autoencoder, which reconstructs the input data itself, neighbor-encoder reconstructs the input data's neighbors. As the proposed representation learning problem is essentially a neighbor reconstruction problem, domain knowledge can be easily incorporated in the form of an appropriate definition of similarity between objects. Based on that observation, our framework can leverage any off-the-shelf similarity search algorithms or side information to find the neighbor of an input object. Applications of other algorithms (e.g., association rule mining) in our framework are also possible, given that the appropriate definition of neighbor can vary in different contexts. We have demonstrated the effectiveness of our framework in many diverse domains, including images, text, and time series, and for various data mining tasks including classification, clustering, and visualization. Experimental results show that neighbor-encoder not only outperforms autoencoder in most of the scenarios we consider, but also achieves the state-of-the-art performance on text document clustering.
Paying Attention to Attention: Highlighting Influential Samples in Sequential Analysis
Aug 06, 2018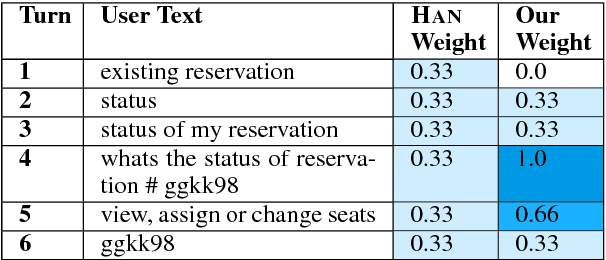
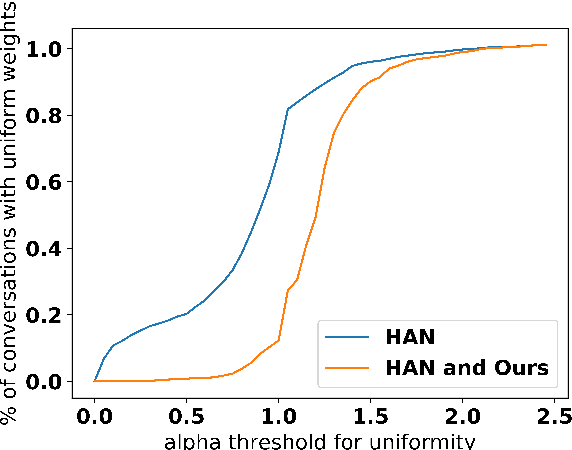
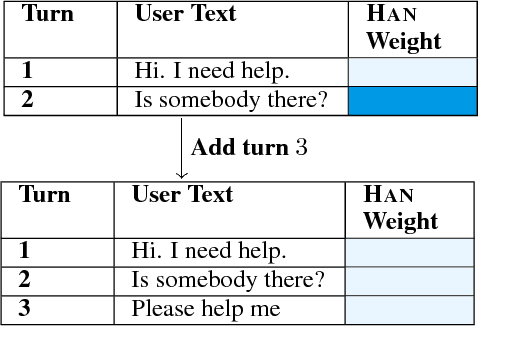
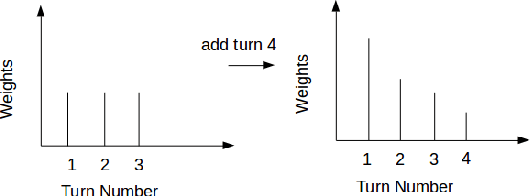
In (Yang et al. 2016), a hierarchical attention network (HAN) is created for document classification. The attention layer can be used to visualize text influential in classifying the document, thereby explaining the model's prediction. We successfully applied HAN to a sequential analysis task in the form of real-time monitoring of turn taking in conversations. However, we discovered instances where the attention weights were uniform at the stopping point (indicating all turns were equivalently influential to the classifier), preventing meaningful visualization for real-time human review or classifier improvement. We observed that attention weights for turns fluctuated as the conversations progressed, indicating turns had varying influence based on conversation state. Leveraging this observation, we develop a method to create more informative real-time visuals (as confirmed by human reviewers) in cases of uniform attention weights using the changes in turn importance as a conversation progresses over time.
Admissible Time Series Motif Discovery with Missing Data
Feb 15, 2018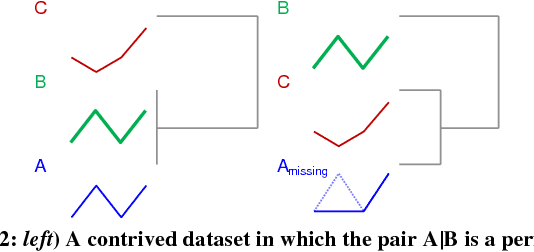
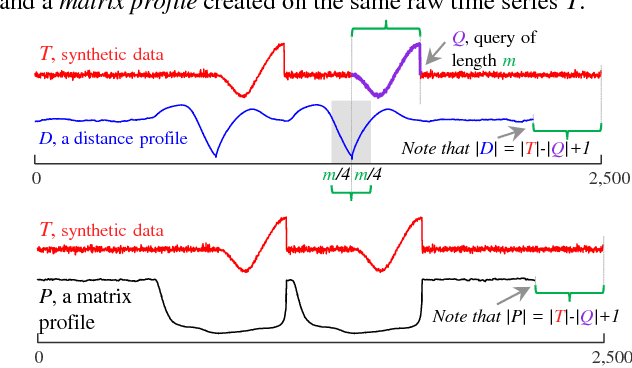
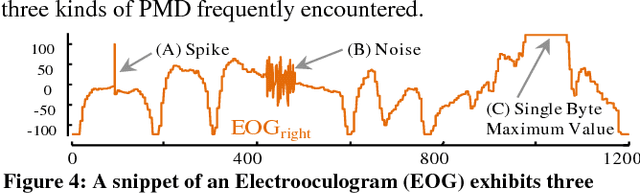
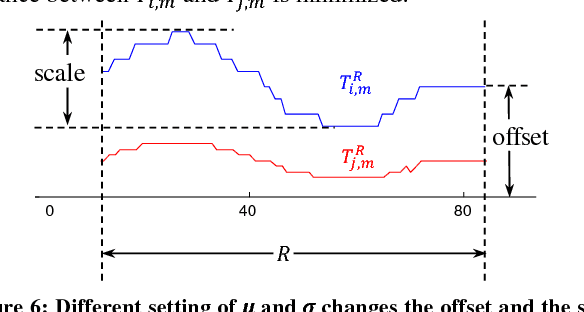
The discovery of time series motifs has emerged as one of the most useful primitives in time series data mining. Researchers have shown its utility for exploratory data mining, summarization, visualization, segmentation, classification, clustering, and rule discovery. Although there has been more than a decade of extensive research, there is still no technique to allow the discovery of time series motifs in the presence of missing data, despite the well-documented ubiquity of missing data in scientific, industrial, and medical datasets. In this work, we introduce a technique for motif discovery in the presence of missing data. We formally prove that our method is admissible, producing no false negatives. We also show that our method can piggy-back off the fastest known motif discovery method with a small constant factor time/space overhead. We will demonstrate our approach on diverse datasets with varying amounts of missing data
An Annotated Corpus of Relational Strategies in Customer Service
Aug 17, 2017
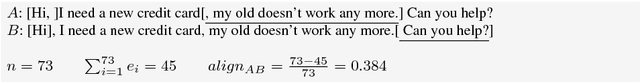


We create and release the first publicly available commercial customer service corpus with annotated relational segments. Human-computer data from three live customer service Intelligent Virtual Agents (IVAs) in the domains of travel and telecommunications were collected, and reviewers marked all text that was deemed unnecessary to the determination of user intention. After merging the selections of multiple reviewers to create highlighted texts, a second round of annotation was done to determine the classes of language present in the highlighted sections such as the presence of Greetings, Backstory, Justification, Gratitude, Rants, or Emotions. This resulting corpus is a valuable resource for improving the quality and relational abilities of IVAs. As well as discussing the corpus itself, we compare the usage of such language in human-human interactions on TripAdvisor forums. We show that removal of this language from task-based inputs has a positive effect on IVA understanding by both an increase in confidence and improvement in responses, demonstrating the need for automated methods of its discovery.