 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-Supervised Deep Clustering Pipeline for Mining Intentions From Texts
Feb 01, 2022Mining the latent intentions from large volumes of natural language inputs is a key step to help data analysts design and refine Intelligent Virtual Assistants (IVAs) for customer service. To aid data analysts in this task we present Verint Intent Manager (VIM), an analysis platform that combines unsupervised and semi-supervised approaches to help analysts quickly surface and organize relevant user intentions from conversational texts. For the initial exploration of data we make use of a novel unsupervised and semi-supervised pipeline that integrates the fine-tuning of high performing language models, a distributed k-NN graph building method and community detection techniques for mining the intentions and topics from texts. The fine-tuning step is necessary because pre-trained language models cannot encode texts to efficiently surface particular clustering structures when the target texts are from an unseen domain or the clustering task is not topic detection. For flexibility we deploy two clustering approaches: where the number of clusters must be specified and where the number of clusters is detected automatically with comparable clustering quality but at the expense of additional computation time. We describe the application and deployment and demonstrate its performance using BERT on three text mining tasks. Our experiments show that BERT begins to produce better task-aware representations using a labeled subset as small as 0.5% of the task data. The clustering quality exceeds the state-of-the-art results when BERT is fine-tuned with labeled subsets of only 2.5% of the task data. As deployed in the VIM application, this flexible clustering pipeline produces high quality results, improving the performance of data analysts and reducing the time it takes to surface intentions from customer service data, thereby reducing the time it takes to build and deploy IVAs in new domains.
A Flexible Clustering Pipeline for Mining Text Intentions
Feb 01, 2022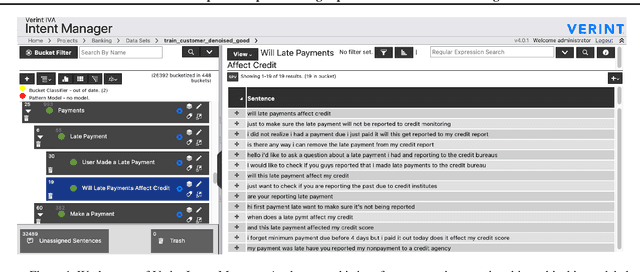



Mining the latent intentions from large volumes of natural language inputs is a key step to help data analysts design and refine Intelligent Virtual Assistants (IVAs) for customer service and sales support. We created a flexible and scalable clustering pipeline within the Verint Intent Manager (VIM) that integrates the fine-tuning of language models, a high performing k-NN library and community detection techniques to help analysts quickly surface and organize relevant user intentions from conversational texts. The fine-tuning step is necessary because pre-trained language models cannot encode texts to efficiently surface particular clustering structures when the target texts are from an unseen domain or the clustering task is not topic detection. We describe the pipeline and demonstrate its performance using BERT on three real-world text mining tasks. As deployed in the VIM application, this clustering pipeline produces high quality results, improving the performance of data analysts and reducing the time it takes to surface intentions from customer service data, thereby reducing the time it takes to build and deploy IVAs in new domains.
TimeVAE: A Variational Auto-Encoder for Multivariate Time Series Generation
Dec 07, 2021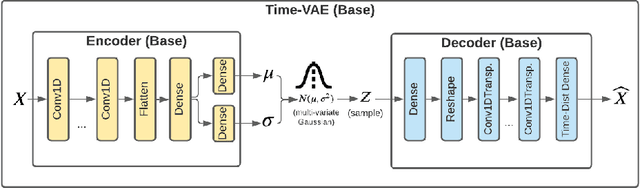

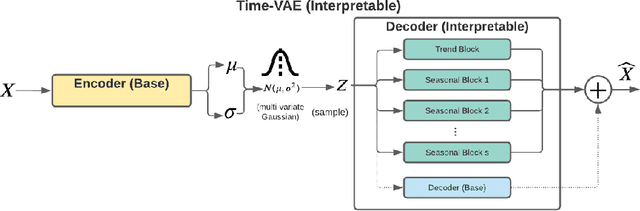
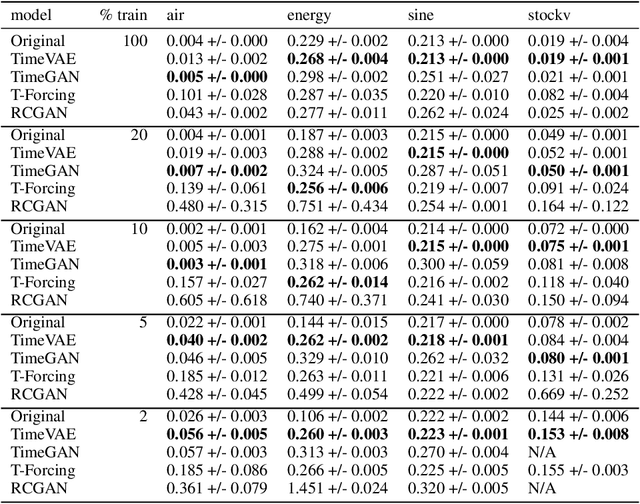
Recent work in synthetic data generation in the time-series domain has focused on the use of Generative Adversarial Networks. We propose a novel architecture for synthetically generating time-series data with the use of Variational Auto-Encoders (VAEs). The proposed architecture has several distinct properties: interpretability, ability to encode domain knowledge, and reduced training times. We evaluate data generation quality by similarity and predictability against four multivariate datasets. We experiment with varying sizes of training data to measure the impact of data availability on generation quality for our VAE method as well as several state-of-the-art data generation methods. Our results on similarity tests show that the VAE approach is able to accurately represent the temporal attributes of the original data. On next-step prediction tasks using generated data, the proposed VAE architecture consistently meets or exceeds performance of state-of-the-art data generation methods. While noise reduction may cause the generated data to deviate from original data, we demonstrate the resulting de-noised data can significantly improve performance for next-step prediction using generated data. Finally, the proposed architecture can incorporate domain-specific time-patterns such as polynomial trends and seasonalities to provide interpretable outputs. Such interpretability can be highly advantageous in applications requiring transparency of model outputs or where users desire to inject prior knowledge of time-series patterns into the generative model.
Paying Attention to Attention: Highlighting Influential Samples in Sequential Analysis
Aug 06, 2018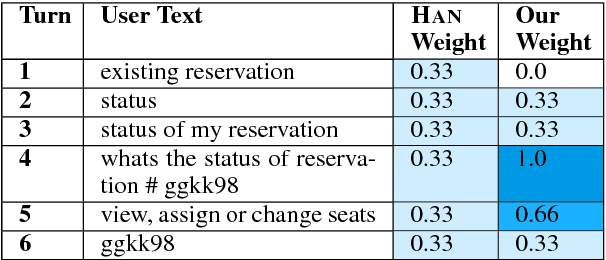
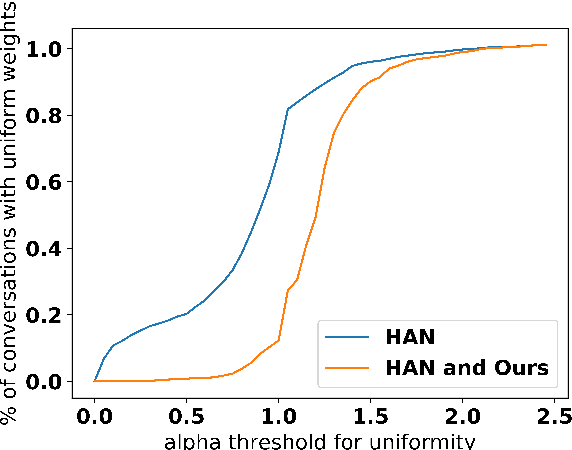
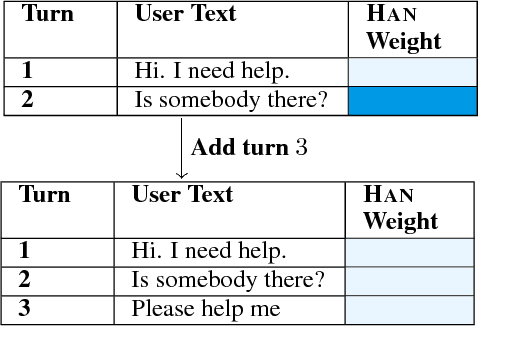
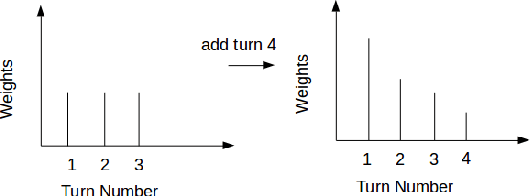
In (Yang et al. 2016), a hierarchical attention network (HAN) is created for document classification. The attention layer can be used to visualize text influential in classifying the document, thereby explaining the model's prediction. We successfully applied HAN to a sequential analysis task in the form of real-time monitoring of turn taking in conversations. However, we discovered instances where the attention weights were uniform at the stopping point (indicating all turns were equivalently influential to the classifier), preventing meaningful visualization for real-time human review or classifier improvement. We observed that attention weights for turns fluctuated as the conversations progressed, indicating turns had varying influence based on conversation state. Leveraging this observation, we develop a method to create more informative real-time visuals (as confirmed by human reviewers) in cases of uniform attention weights using the changes in turn importance as a conversation progresses over time.
An Annotated Corpus of Relational Strategies in Customer Service
Aug 17, 2017
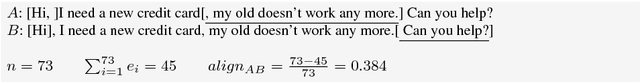


We create and release the first publicly available commercial customer service corpus with annotated relational segments. Human-computer data from three live customer service Intelligent Virtual Agents (IVAs) in the domains of travel and telecommunications were collected, and reviewers marked all text that was deemed unnecessary to the determination of user intention. After merging the selections of multiple reviewers to create highlighted texts, a second round of annotation was done to determine the classes of language present in the highlighted sections such as the presence of Greetings, Backstory, Justification, Gratitude, Rants, or Emotions. This resulting corpus is a valuable resource for improving the quality and relational abilities of IVAs. As well as discussing the corpus itself, we compare the usage of such language in human-human interactions on TripAdvisor forums. We show that removal of this language from task-based inputs has a positive effect on IVA understanding by both an increase in confidence and improvement in responses, demonstrating the need for automated methods of its discovery.