 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing the Scales: A Comprehensive Study on Tackling Class Imbalance in Binary Classification
Sep 29, 2024Class imbalance in binary classification tasks remains a significant challenge in machine learning, often resulting in poor performance on minority classes. This study comprehensively evaluates three widely-used strategies for handling class imbalance: Synthetic Minority Over-sampling Technique (SMOTE), Class Weights tuning, and Decision Threshold Calibration. We compare these methods against a baseline scenario of no-intervention across 15 diverse machine learning models and 30 datasets from various domains, conducting a total of 9,000 experiments. Performance was primarily assessed using the F1-score, although our study also tracked results on additional 9 metrics including F2-score, precision, recall, Brier-score, PR-AUC, and AUC. Our results indicate that all three strategies generally outperform the baseline, with Decision Threshold Calibration emerging as the most consistently effective technique. However, we observed substantial variability in the best-performing method across datasets, highlighting the importance of testing multiple approaches for specific problems. This study provides valuable insights for practitioners dealing with imbalanced datasets and emphasizes the need for dataset-specific analysis in evaluating class imbalance handling techniques.
TimeVAE: A Variational Auto-Encoder for Multivariate Time Series Generation
Dec 07, 2021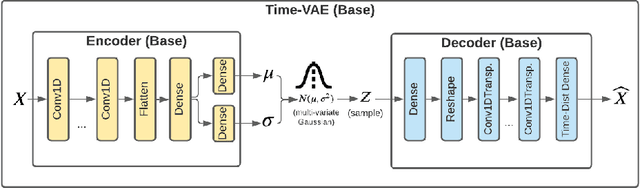

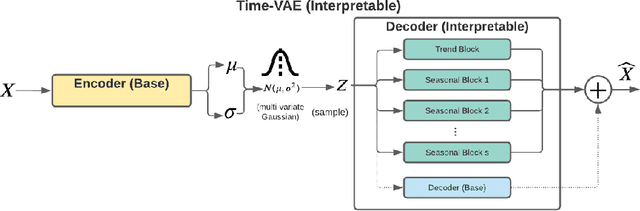
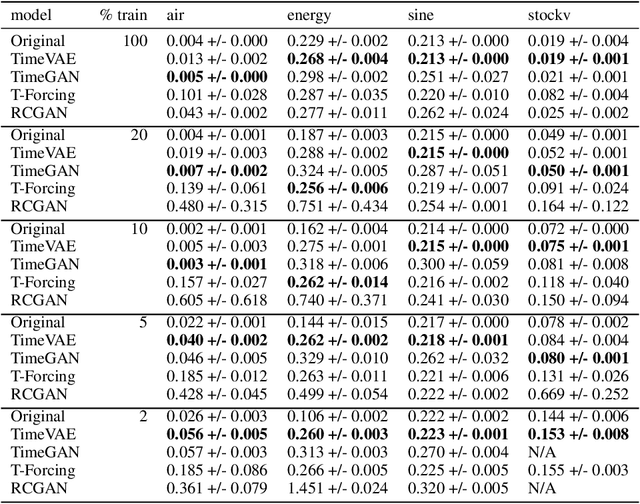
Recent work in synthetic data generation in the time-series domain has focused on the use of Generative Adversarial Networks. We propose a novel architecture for synthetically generating time-series data with the use of Variational Auto-Encoders (VAEs). The proposed architecture has several distinct properties: interpretability, ability to encode domain knowledge, and reduced training times. We evaluate data generation quality by similarity and predictability against four multivariate datasets. We experiment with varying sizes of training data to measure the impact of data availability on generation quality for our VAE method as well as several state-of-the-art data generation methods. Our results on similarity tests show that the VAE approach is able to accurately represent the temporal attributes of the original data. On next-step prediction tasks using generated data, the proposed VAE architecture consistently meets or exceeds performance of state-of-the-art data generation methods. While noise reduction may cause the generated data to deviate from original data, we demonstrate the resulting de-noised data can significantly improve performance for next-step prediction using generated data. Finally, the proposed architecture can incorporate domain-specific time-patterns such as polynomial trends and seasonalities to provide interpretable outputs. Such interpretability can be highly advantageous in applications requiring transparency of model outputs or where users desire to inject prior knowledge of time-series patterns into the generative model.