 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdmissible Time Series Motif Discovery with Missing Data
Paper and Code
Feb 15, 2018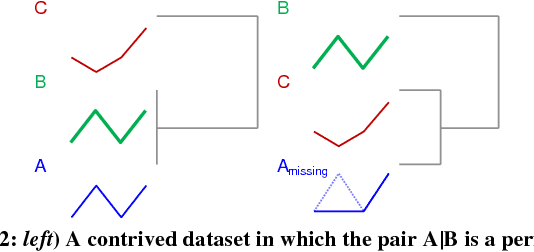
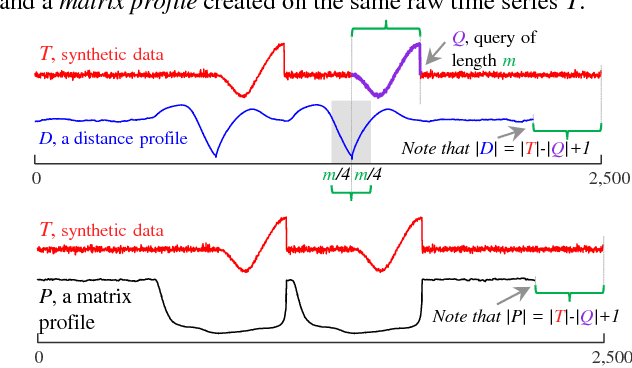
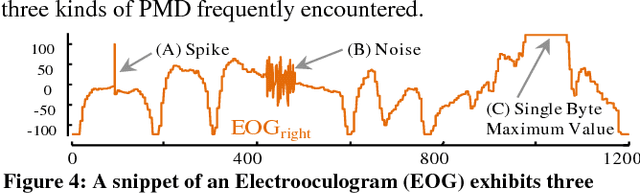
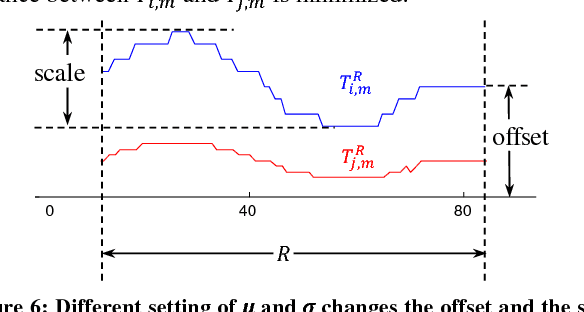
The discovery of time series motifs has emerged as one of the most useful primitives in time series data mining. Researchers have shown its utility for exploratory data mining, summarization, visualization, segmentation, classification, clustering, and rule discovery. Although there has been more than a decade of extensive research, there is still no technique to allow the discovery of time series motifs in the presence of missing data, despite the well-documented ubiquity of missing data in scientific, industrial, and medical datasets. In this work, we introduce a technique for motif discovery in the presence of missing data. We formally prove that our method is admissible, producing no false negatives. We also show that our method can piggy-back off the fastest known motif discovery method with a small constant factor time/space overhead. We will demonstrate our approach on diverse datasets with varying amounts of missing data