 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning by Reconstructing Neighborhoods
Paper and Code
Nov 06, 2018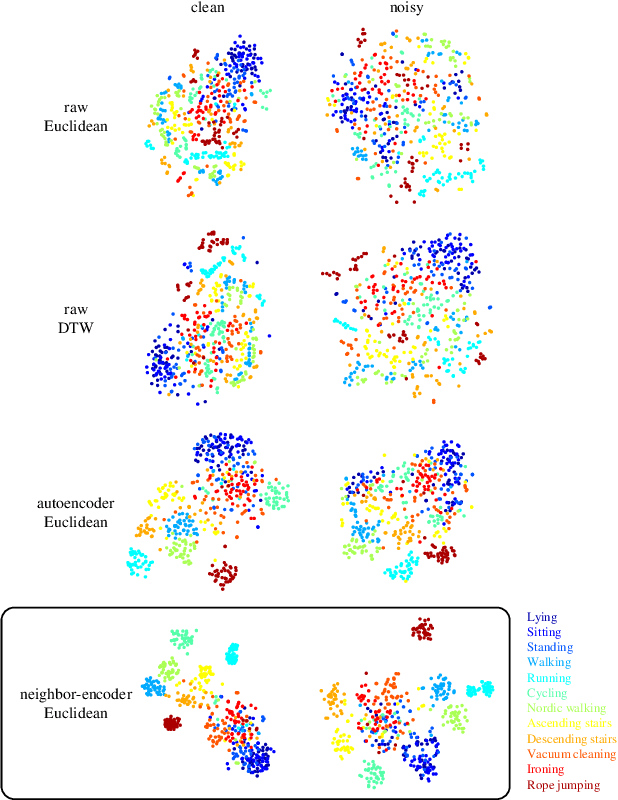
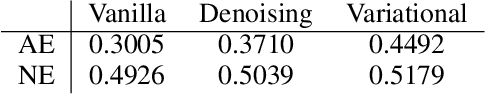
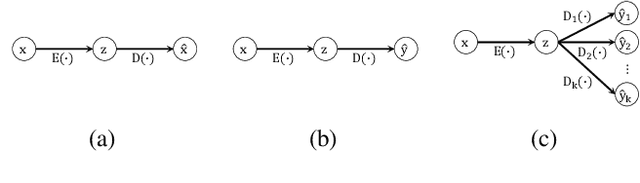
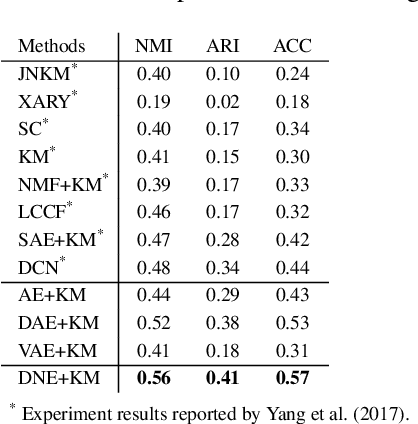
Since its introduction, unsupervised representation learning has attracted a lot of attention from the research community, as it is demonstrated to be highly effective and easy-to-apply in tasks such as dimension reduction, clustering, visualization, information retrieval, and semi-supervised learning. In this work, we propose a novel unsupervised representation learning framework called neighbor-encoder, in which domain knowledge can be easily incorporated into the learning process without modifying the general encoder-decoder architecture of the classic autoencoder.In contrast to autoencoder, which reconstructs the input data itself, neighbor-encoder reconstructs the input data's neighbors. As the proposed representation learning problem is essentially a neighbor reconstruction problem, domain knowledge can be easily incorporated in the form of an appropriate definition of similarity between objects. Based on that observation, our framework can leverage any off-the-shelf similarity search algorithms or side information to find the neighbor of an input object. Applications of other algorithms (e.g., association rule mining) in our framework are also possible, given that the appropriate definition of neighbor can vary in different contexts. We have demonstrated the effectiveness of our framework in many diverse domains, including images, text, and time series, and for various data mining tasks including classification, clustering, and visualization. Experimental results show that neighbor-encoder not only outperforms autoencoder in most of the scenarios we consider, but also achieves the state-of-the-art performance on text document clustering.