 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPrompt: Exploring the Extreme of Prompt Tuning
Paper and Code
Oct 10, 2022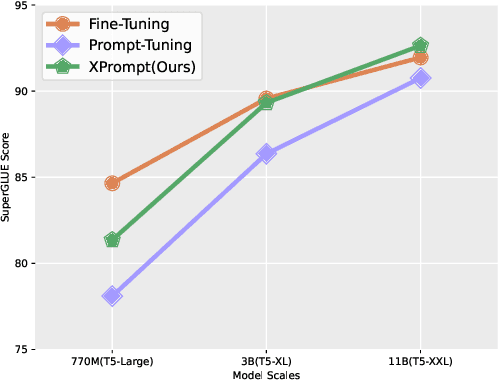
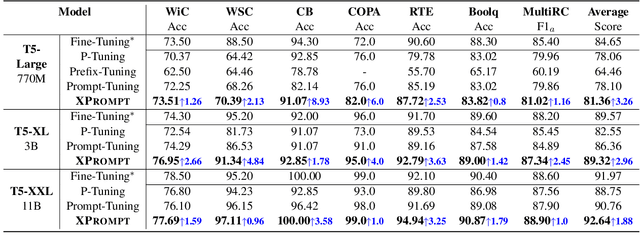
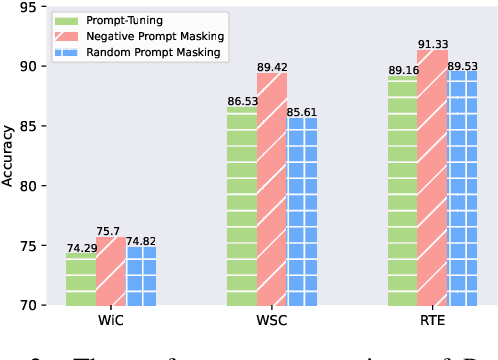
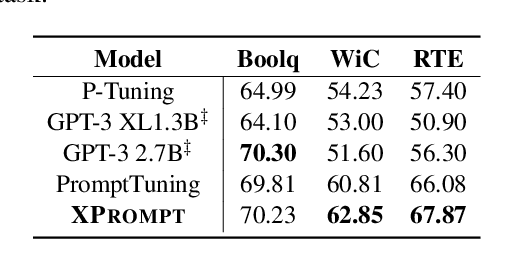
Prompt tuning learns soft prompts to condition frozen Pre-trained Language Models (PLMs) for performing downstream tasks in a parameter-efficient manner. While prompt tuning has gradually reached the performance level of fine-tuning as the model scale increases, there is still a large performance gap between prompt tuning and fine-tuning for models of moderate and small scales (typically less than 11B parameters). In this paper, we empirically show that the trained prompt tokens can have a negative impact on a downstream task and thus degrade its performance. To bridge the gap, we propose a novel Prompt tuning model with an eXtremely small scale (XPrompt) under the regime of lottery tickets hypothesis. Specifically, XPrompt eliminates the negative prompt tokens at different granularity levels through a hierarchical structured pruning, yielding a more parameter-efficient prompt yet with a competitive performance. Comprehensive experiments are carried out on SuperGLUE tasks, and the extensive results indicate that XPrompt is able to close the performance gap at smaller model scales.