 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-Lens-2: Gateway to Omni-modal Intelligence
Paper and Code
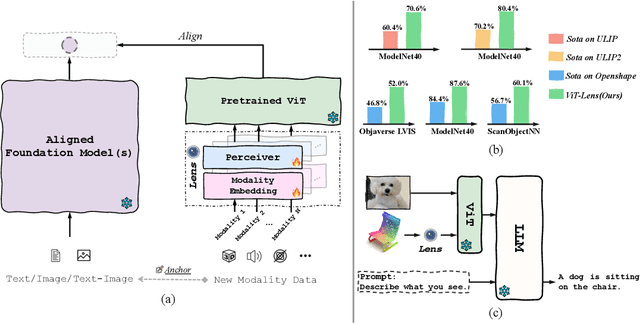
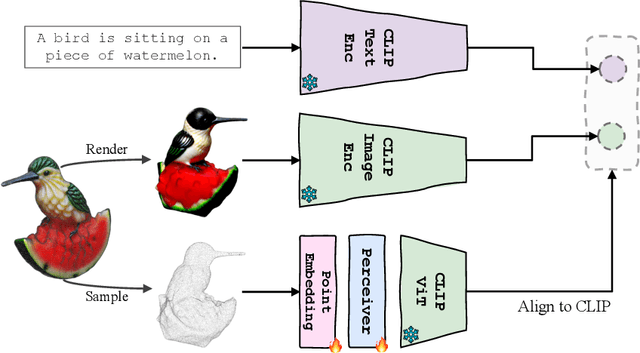
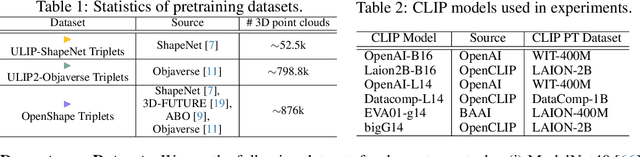
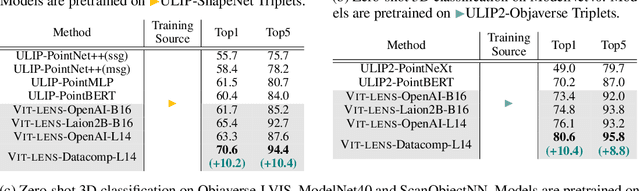
Aiming to advance AI agents, large foundation models significantly improve reasoning and instruction execution, yet the current focus on vision and language neglects the potential of perceiving diverse modalities in open-world environments. However, the success of data-driven vision and language models is costly or even infeasible to be reproduced for rare modalities. In this paper, we present ViT-Lens-2 that facilitates efficient omni-modal representation learning by perceiving novel modalities with a pretrained ViT and aligning them to a pre-defined space. Specifically, the modality-specific lens is tuned to project any-modal signals to an intermediate embedding space, which are then processed by a strong ViT with pre-trained visual knowledge. The encoded representations are optimized toward aligning with the modal-independent space, pre-defined by off-the-shelf foundation models. ViT-Lens-2 provides a unified solution for representation learning of increasing modalities with two appealing advantages: (i) Unlocking the great potential of pretrained ViTs to novel modalities effectively with efficient data regime; (ii) Enabling emergent downstream capabilities through modality alignment and shared ViT parameters. We tailor ViT-Lens-2 to learn representations for 3D point cloud, depth, audio, tactile and EEG, and set new state-of-the-art results across various understanding tasks, such as zero-shot classification. By seamlessly integrating ViT-Lens-2 into Multimodal Foundation Models, we enable Any-modality to Text and Image Generation in a zero-shot manner. Code and models are available at https://github.com/TencentARC/ViT-Lens.