 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompt Tuning for Generative Transfer Learning
Paper and Code
Oct 03, 2022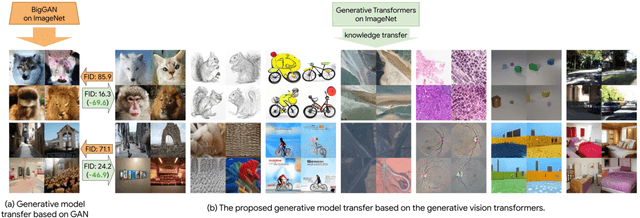
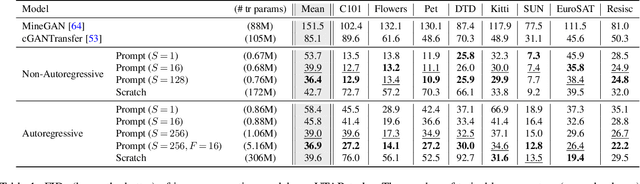
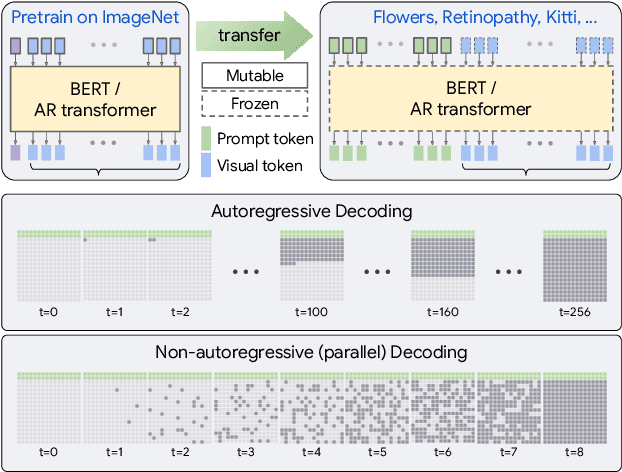
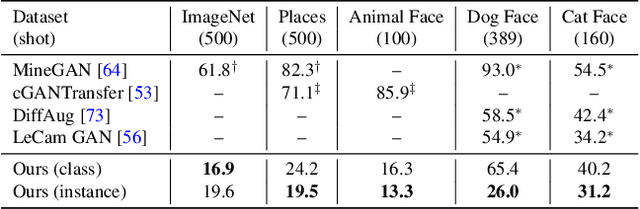
Transferring knowledge from an image synthesis model trained on a large dataset is a promising direction for learning generative image models from various domains efficiently. While previous works have studied GAN models, we present a recipe for learning vision transformers by generative knowledge transfer. We base our framework on state-of-the-art generative vision transformers that represent an image as a sequence of visual tokens to the autoregressive or non-autoregressive transformers. To adapt to a new domain, we employ prompt tuning, which prepends learnable tokens called prompt to the image token sequence, and introduce a new prompt design for our task. We study on a variety of visual domains, including visual task adaptation benchmark~\cite{zhai2019large}, with varying amount of training images, and show effectiveness of knowledge transfer and a significantly better image generation quality over existing works.