 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCon: Unified Context Network for Robust Active Speaker Detection
Paper and Code

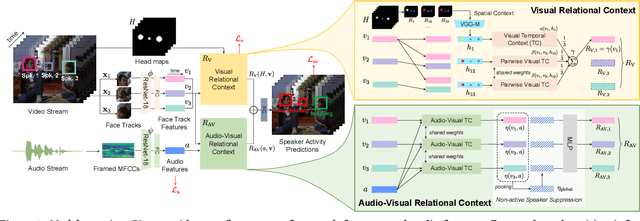
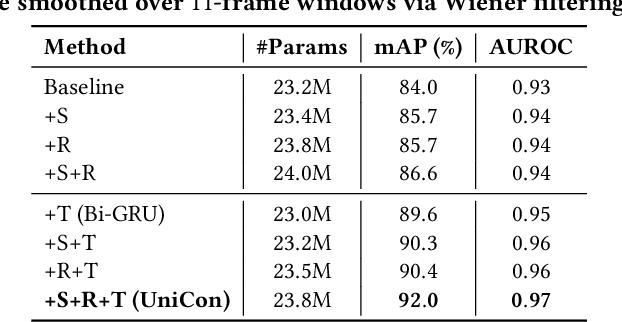

We introduce a new efficient framework, the Unified Context Network (UniCon), for robust active speaker detection (ASD). Traditional methods for ASD usually operate on each candidate's pre-cropped face track separately and do not sufficiently consider the relationships among the candidates. This potentially limits performance, especially in challenging scenarios with low-resolution faces, multiple candidates, etc. Our solution is a novel, unified framework that focuses on jointly modeling multiple types of contextual information: spatial context to indicate the position and scale of each candidate's face, relational context to capture the visual relationships among the candidates and contrast audio-visual affinities with each other, and temporal context to aggregate long-term information and smooth out local uncertainties. Based on such information, our model optimizes all candidates in a unified process for robust and reliable ASD. A thorough ablation study is performed on several challenging ASD benchmarks under different settings. In particular, our method outperforms the state-of-the-art by a large margin of about 15% mean Average Precision (mAP) absolute on two challenging subsets: one with three candidate speakers, and the other with faces smaller than 64 pixels. Together, our UniCon achieves 92.0% mAP on the AVA-ActiveSpeaker validation set, surpassing 90% for the first time on this challenging dataset at the time of submission. Project website: https://unicon-asd.github.io/.