 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding or Manipulation: Rethinking Online Performance Gains of Modern Recommender Systems
Paper and Code
Oct 11, 2022
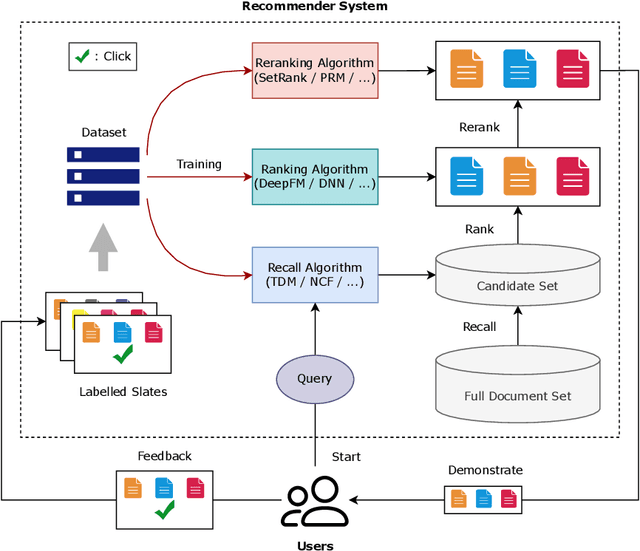
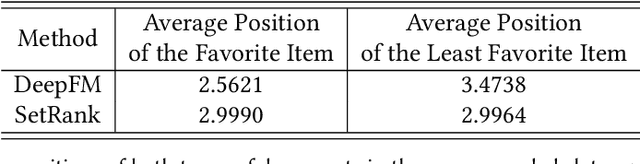
Recommender systems are expected to be assistants that help human users find relevant information in an automatic manner without explicit queries. As recommender systems evolve, increasingly sophisticated learning techniques are applied and have achieved better performance in terms of user engagement metrics such as clicks and browsing time. The increase of the measured performance, however, can have two possible attributions: a better understanding of user preferences, and a more proactive ability to utilize human bounded rationality to seduce user over-consumption. A natural following question is whether current recommendation algorithms are manipulating user preferences. If so, can we measure the manipulation level? In this paper, we present a general framework for benchmarking the degree of manipulations of recommendation algorithms, in both slate recommendation and sequential recommendation scenarios. The framework consists of three stages, initial preference calculation, algorithm training and interaction, and metrics calculation that involves two proposed metrics, Manipulation Score and Preference Shift. We benchmark some representative recommendation algorithms in both synthetic and real-world datasets under the proposed framework. We have observed that a high online click-through rate does not mean a better understanding of user initial preference, but ends in prompting users to choose more documents they initially did not favor. Moreover, we find that the properties of training data have notable impacts on the manipulation degrees, and algorithms with more powerful modeling abilities are more sensitive to such impacts. The experiments also verified the usefulness of the proposed metrics for measuring the degree of manipulations. We advocate that future recommendation algorithm studies should be treated as an optimization problem with constrained user preference manipulations.