 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking and Reconstructing Hand Object Interactions from Point Cloud Sequences in the Wild
Paper and Code
Sep 24, 2022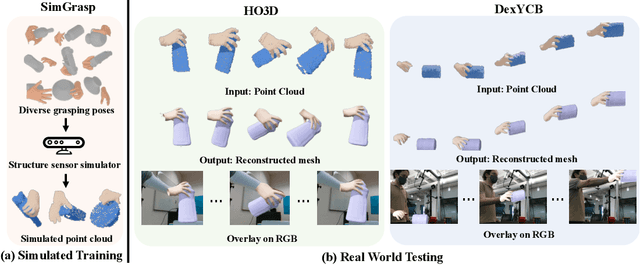
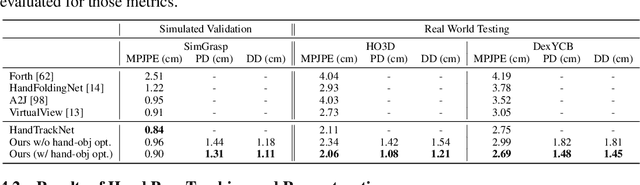
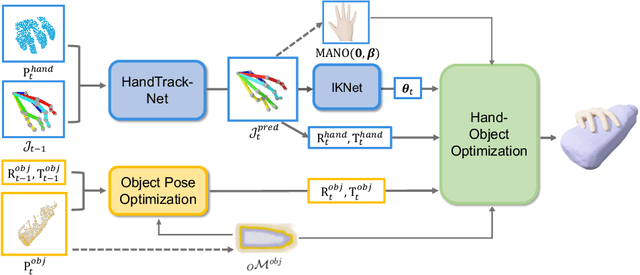
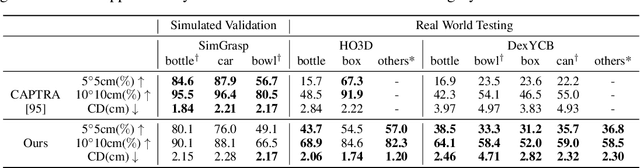
In this work, we tackle the challenging task of jointly tracking hand object pose and reconstructing their shapes from depth point cloud sequences in the wild, given the initial poses at frame 0. We for the first time propose a point cloud based hand joint tracking network, HandTrackNet, to estimate the inter-frame hand joint motion. Our HandTrackNet proposes a novel hand pose canonicalization module to ease the tracking task, yielding accurate and robust hand joint tracking. Our pipeline then reconstructs the full hand via converting the predicted hand joints into a template-based parametric hand model MANO. For object tracking, we devise a simple yet effective module that estimates the object SDF from the first frame and performs optimization-based tracking. Finally, a joint optimization step is adopted to perform joint hand and object reasoning, which alleviates the occlusion-induced ambiguity and further refines the hand pose. During training, the whole pipeline only sees purely synthetic data, which are synthesized with sufficient variations and by depth simulation for the ease of generalization. The whole pipeline is pertinent to the generalization gaps and thus directly transferable to real in-the-wild data. We evaluate our method on two real hand object interaction datasets, e.g. HO3D and DexYCB, without any finetuning. Our experiments demonstrate that the proposed method significantly outperforms the previous state-of-the-art depth-based hand and object pose estimation and tracking methods, running at a frame rate of 9 FPS.