 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Labeling: Training a 85.4% Top-1 Accuracy Vision Transformer with 56M Parameters on ImageNet
Paper and Code
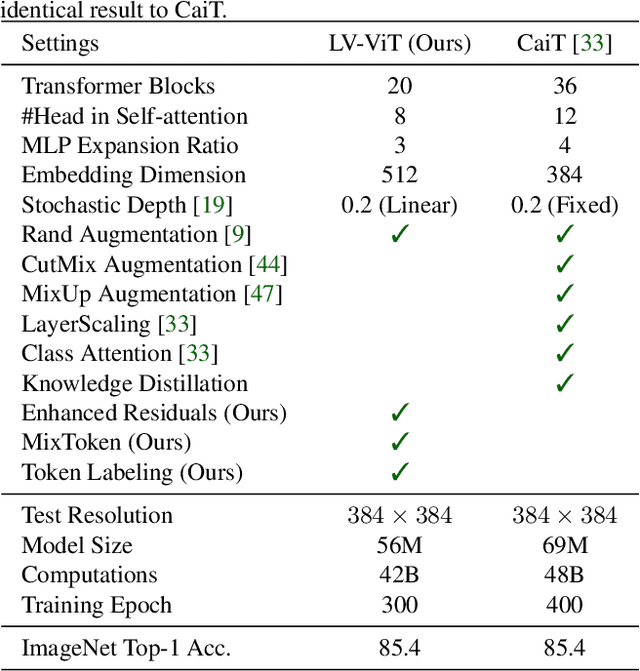
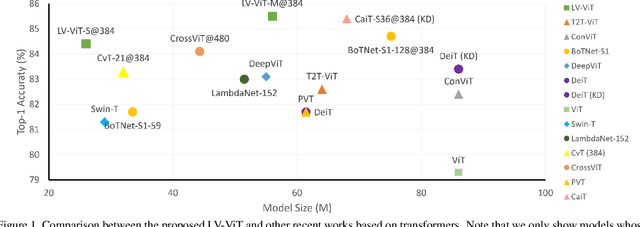
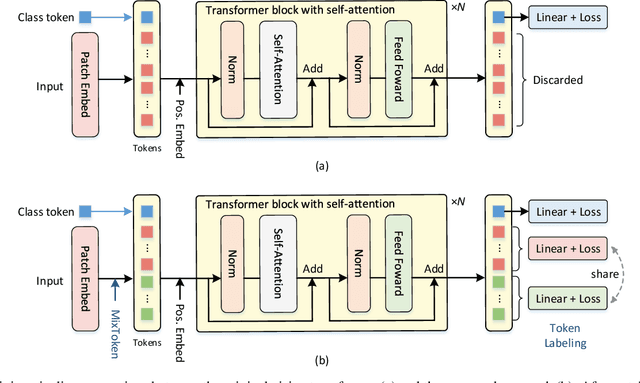
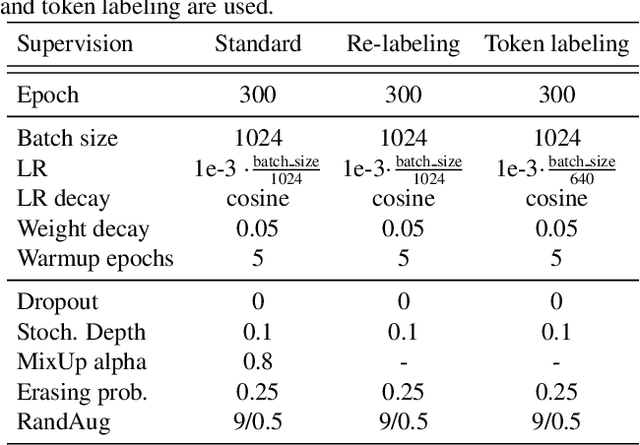
This paper provides a strong baseline for vision transformers on the ImageNet classification task. While recent vision transformers have demonstrated promising results in ImageNet classification, their performance still lags behind powerful convolutional neural networks (CNNs) with approximately the same model size. In this work, instead of describing a novel transformer architecture, we explore the potential of vision transformers in ImageNet classification by developing a bag of training techniques. We show that by slightly tuning the structure of vision transformers and introducing token labeling -- a new training objective, our models are able to achieve better results than the CNN counterparts and other transformer-based classification models with similar amount of training parameters and computations. Taking a vision transformer with 26M learnable parameters as an example, we can achieve an 84.4% Top-1 accuracy on ImageNet. When the model size is scaled up to 56M/150M, the result can be further increased to 85.4%/86.2% without extra data. We hope this study could provide researchers with useful techniques to train powerful vision transformers. Our code and all the training details will be made publicly available at https://github.com/zihangJiang/TokenLabeling.