 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-Dimensional Medical Image Fusion with Deformable Cross-Attention
Paper and Code
Oct 10, 2023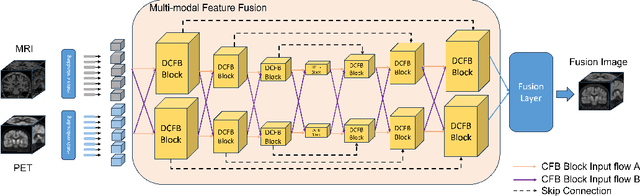
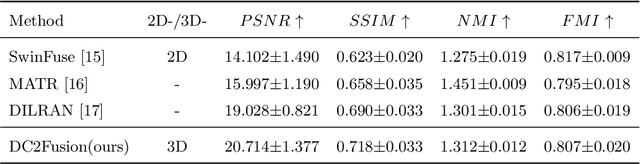
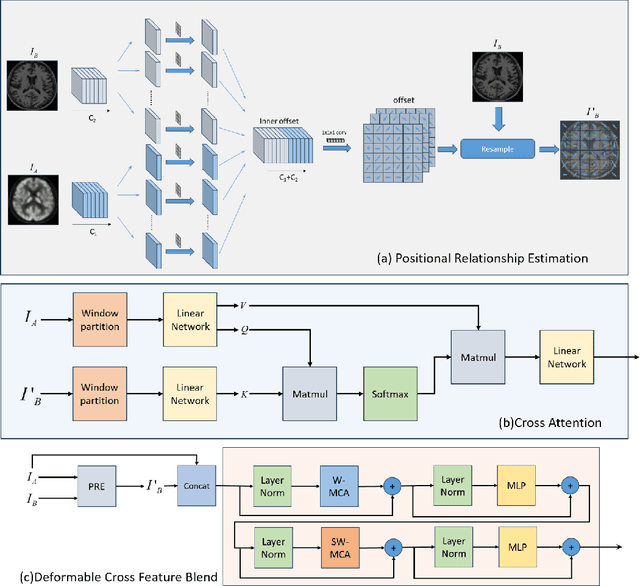
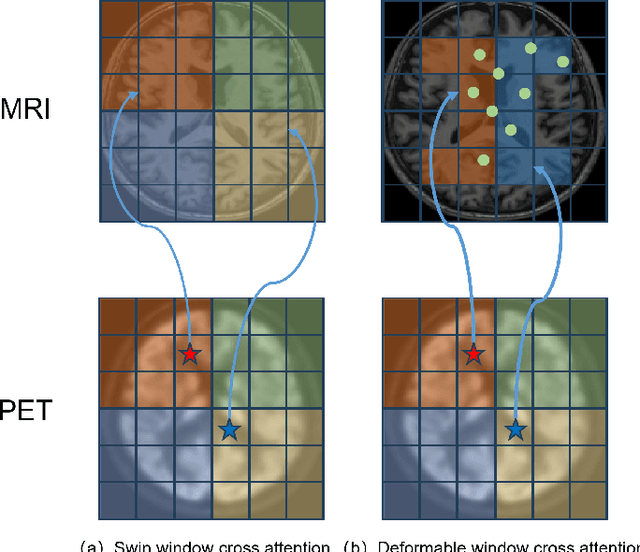
Multimodal medical image fusion plays an instrumental role in several areas of medical image processing, particularly in disease recognition and tumor detection. Traditional fusion methods tend to process each modality independently before combining the features and reconstructing the fusion image. However, this approach often neglects the fundamental commonalities and disparities between multimodal information. Furthermore, the prevailing methodologies are largely confined to fusing two-dimensional (2D) medical image slices, leading to a lack of contextual supervision in the fusion images and subsequently, a decreased information yield for physicians relative to three-dimensional (3D) images. In this study, we introduce an innovative unsupervised feature mutual learning fusion network designed to rectify these limitations. Our approach incorporates a Deformable Cross Feature Blend (DCFB) module that facilitates the dual modalities in discerning their respective similarities and differences. We have applied our model to the fusion of 3D MRI and PET images obtained from 660 patients in the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Through the application of the DCFB module, our network generates high-quality MRI-PET fusion images. Experimental results demonstrate that our method surpasses traditional 2D image fusion methods in performance metrics such as Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM). Importantly, the capacity of our method to fuse 3D images enhances the information available to physicians and researchers, thus marking a significant step forward in the field. The code will soon be available online.