 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Secret Revealer: Generative Model-Inversion Attacks Against Deep Neural Networks
Paper and Code
Nov 17, 2019

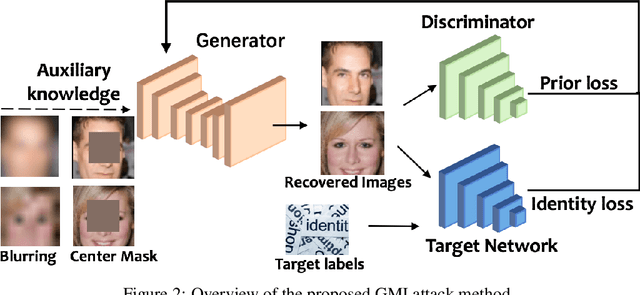

This paper studies model-inversion attacks, in which the access to a model is abused to infer information about the training data. Since its first introduction by~\citet{fredrikson2014privacy}, such attacks have raised serious concerns given that training data usually contain privacy sensitive information. Thus far, successful model-inversion attacks have only been demonstrated on simple models, such as linear regression and logistic regression. Previous attempts to invert neural networks, even the ones with simple architectures, have failed to produce convincing results. Here we present a novel attack method, termed the \emph{generative model-inversion attack}, which can invert deep neural networks with high success rates. Rather than reconstructing private training data from scratch, we leverage partial public information, which can be very generic, to learn a distributional prior via generative adversarial networks (GANs) and use it to guide the inversion process. Moreover, we theoretically prove that a model's predictive power and its vulnerability to inversion attacks are indeed two sides of the same coin---highly predictive models are able to establish a strong correlation between features and labels, which coincides exactly with what an adversary exploits to mount the attacks. Our extensive experiments demonstrate that the proposed attack improves identification accuracy over the existing work by about $75\%$ for reconstructing face images from a state-of-the-art face recognition classifier. We also show that differential privacy, in its canonical form, is of little avail to defend against our attacks.