 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTADRN: Triple-Attentive Dual-Recurrent Network for Ad-hoc Array Multichannel Speech Enhancement
Paper and Code



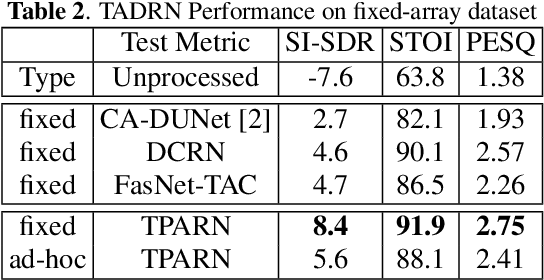
Deep neural networks (DNNs) have been successfully used for multichannel speech enhancement in fixed array geometries. However, challenges remain for ad-hoc arrays with unknown microphone placements. We propose a deep neural network based approach for ad-hoc array processing: Triple-Attentive Dual-Recurrent Network (TADRN). TADRN uses self-attention across channels for learning spatial information and a dual-path attentive recurrent network (ARN) for temporal modeling. Temporal modeling is done independently for all channels by dividing a signal into smaller chunks and using an intra-chunk ARN for local modeling and an inter-chunk ARN for global modeling. Consequently, TADRN uses triple-path attention: inter-channel, intra-chunk, and inter-chunk, and dual-path recurrence: intra-chunk and inter-chunk. Experimental results show excellent performance of TADRN. We demonstrate that TADRN improves speech enhancement by leveraging additional randomly placed microphones, even at locations far from the target source. Additionally, large improvements in objective scores are observed when poorly placed microphones in the scene are complemented with more effective microphone positions, such as those closer to a target source.