 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
Paper and Code
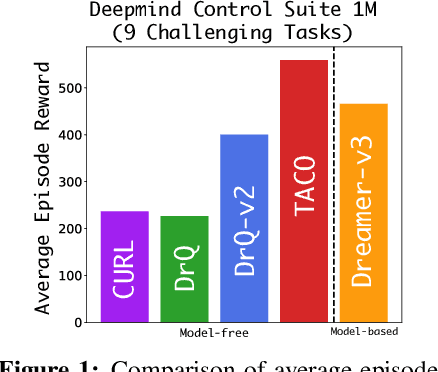



Despite recent progress in reinforcement learning (RL) from raw pixel data, sample inefficiency continues to present a substantial obstacle. Prior works have attempted to address this challenge by creating self-supervised auxiliary tasks, aiming to enrich the agent's learned representations with control-relevant information for future state prediction. However, these objectives are often insufficient to learn representations that can represent the optimal policy or value function, and they often consider tasks with small, abstract discrete action spaces and thus overlook the importance of action representation learning in continuous control. In this paper, we introduce TACO: Temporal Action-driven Contrastive Learning, a simple yet powerful temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents. TACO simultaneously learns a state and an action representation by optimizing the mutual information between representations of current states paired with action sequences and representations of the corresponding future states. Theoretically, TACO can be shown to learn state and action representations that encompass sufficient information for control, thereby improving sample efficiency. For online RL, TACO achieves 40% performance boost after one million environment interaction steps on average across nine challenging visual continuous control tasks from Deepmind Control Suite. In addition, we show that TACO can also serve as a plug-and-play module adding to existing offline visual RL methods to establish the new state-of-the-art performance for offline visual RL across offline datasets with varying quality.