Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleDGPT: Stylized Response Generation with Pre-trained Language Models
Paper and Code
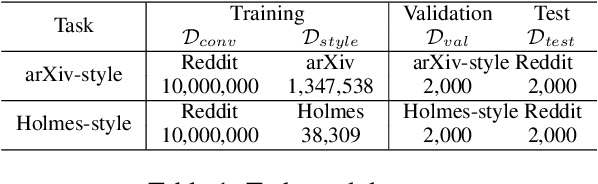



Generating responses following a desired style has great potentials to extend applications of open-domain dialogue systems, yet is refrained by lacking of parallel data for training. In this work, we explore the challenging task with pre-trained language models that have brought breakthrough to various natural language tasks. To this end, we introduce a KL loss and a style classifier to the fine-tuning step in order to steer response generation towards the target style in both a word-level and a sentence-level. Comprehensive empirical studies with two public datasets indicate that our model can significantly outperform state-of-the-art methods in terms of both style consistency and contextual coherence.
* Findings of EMNLP2020
View paper on