 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpach Transformer: Spatial and Channel-wise Transformer Based on Local and Global Self-attentions for PET Image Denoising
Paper and Code
Sep 07, 2022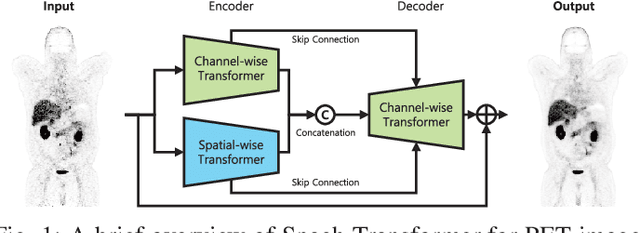
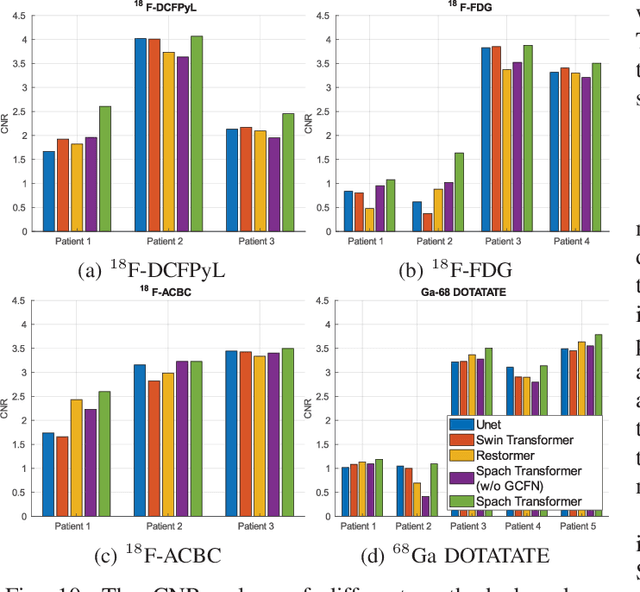
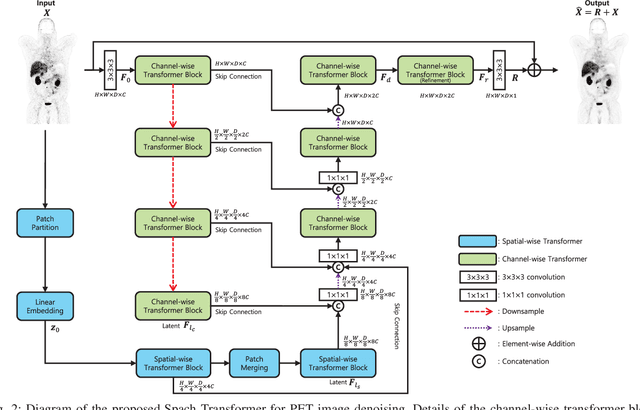
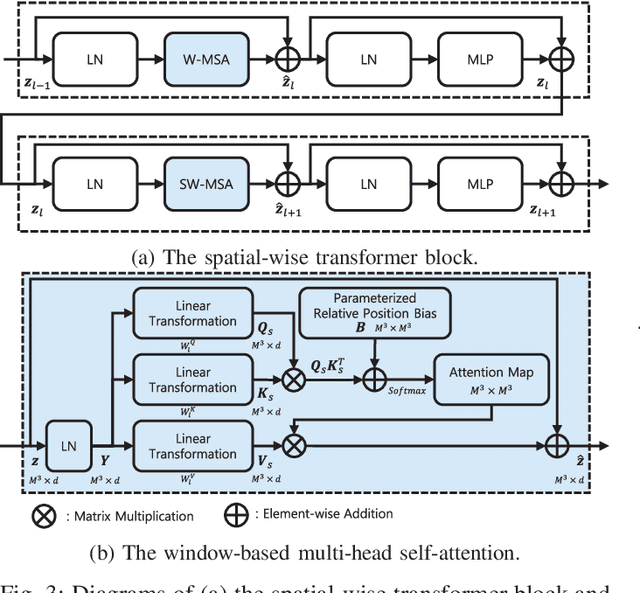
Position emission tomography (PET) is widely used in clinics and research due to its quantitative merits and high sensitivity, but suffers from low signal-to-noise ratio (SNR). Recently convolutional neural networks (CNNs) have been widely used to improve PET image quality. Though successful and efficient in local feature extraction, CNN cannot capture long-range dependencies well due to its limited receptive field. Global multi-head self-attention (MSA) is a popular approach to capture long-range information. However, the calculation of global MSA for 3D images has high computational costs. In this work, we proposed an efficient spatial and channel-wise encoder-decoder transformer, Spach Transformer, that can leverage spatial and channel information based on local and global MSAs. Experiments based on datasets of different PET tracers, i.e., $^{18}$F-FDG, $^{18}$F-ACBC, $^{18}$F-DCFPyL, and $^{68}$Ga-DOTATATE, were conducted to evaluate the proposed framework. Quantitative results show that the proposed Spach Transformer can achieve better performance than other reference methods.