Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Speech-to-Speech Translation System with Neural Incremental ASR, MT, and TTS
Paper and Code
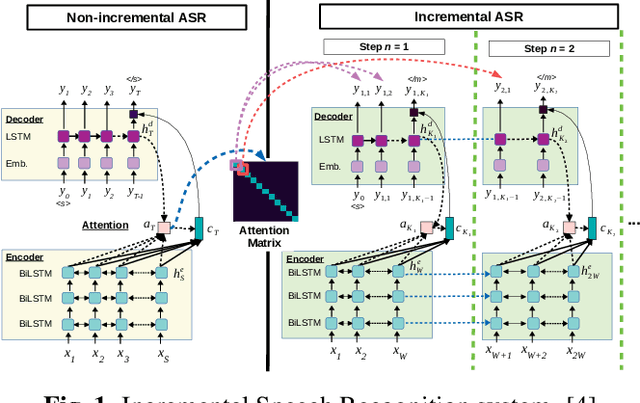
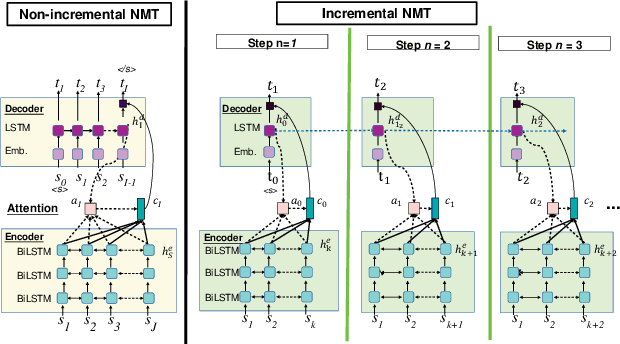
This paper presents a newly developed, simultaneous neural speech-to-speech translation system and its evaluation. The system consists of three fully-incremental neural processing modules for automatic speech recognition (ASR), machine translation (MT), and text-to-speech synthesis (TTS). We investigated its overall latency in the system's Ear-Voice Span and speaking latency along with module-level performance.
* 6 pages
View paper on