 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShifting More Attention to Visual Backbone: Query-modulated Refinement Networks for End-to-End Visual Grounding
Paper and Code



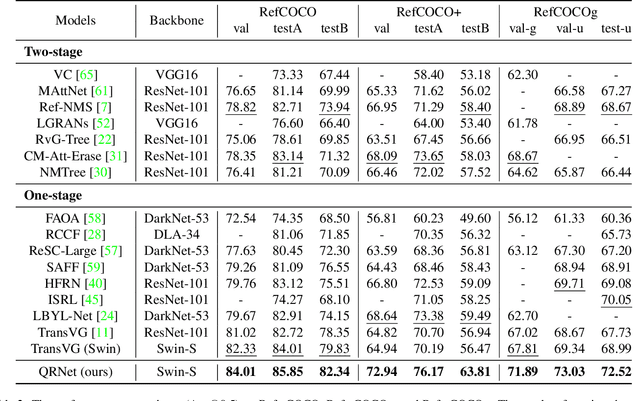
Visual grounding focuses on establishing fine-grained alignment between vision and natural language, which has essential applications in multimodal reasoning systems. Existing methods use pre-trained query-agnostic visual backbones to extract visual feature maps independently without considering the query information. We argue that the visual features extracted from the visual backbones and the features really needed for multimodal reasoning are inconsistent. One reason is that there are differences between pre-training tasks and visual grounding. Moreover, since the backbones are query-agnostic, it is difficult to completely avoid the inconsistency issue by training the visual backbone end-to-end in the visual grounding framework. In this paper, we propose a Query-modulated Refinement Network (QRNet) to address the inconsistent issue by adjusting intermediate features in the visual backbone with a novel Query-aware Dynamic Attention (QD-ATT) mechanism and query-aware multiscale fusion. The QD-ATT can dynamically compute query-dependent visual attention at the spatial and channel levels of the feature maps produced by the visual backbone. We apply the QRNet to an end-to-end visual grounding framework. Extensive experiments show that the proposed method outperforms state-of-the-art methods on five widely used datasets.