 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling description of generalization with number of parameters in deep learning
Paper and Code
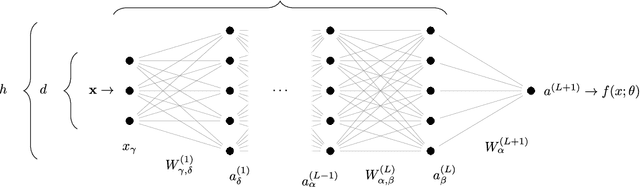
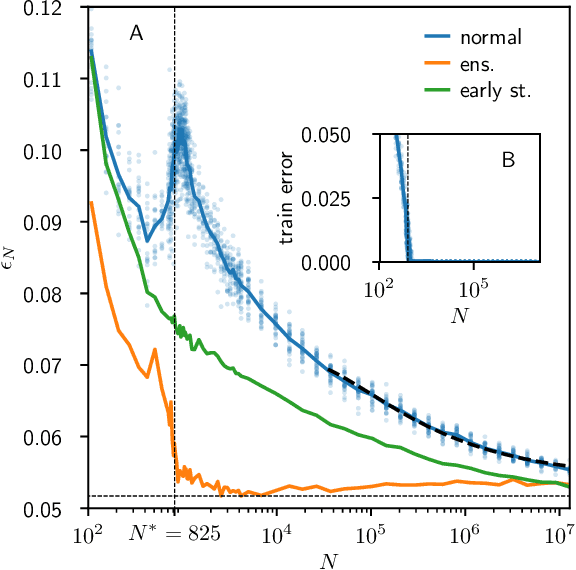
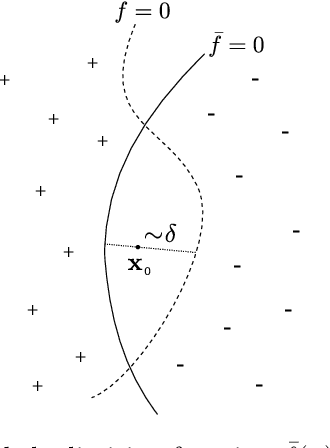
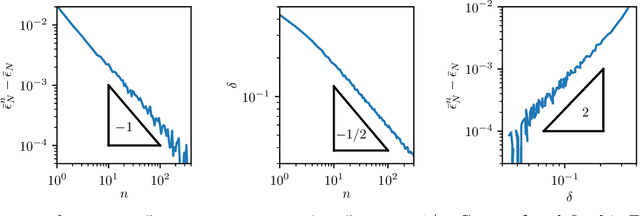
We provide a description for the evolution of the generalization performance of fixed-depth fully-connected deep neural networks as a function of the number of parameters $N$. We observe that increasing $N$ at fixed depth reduces the fluctuations of the output function $f_N$ induced by initial conditions, with $\Vert f_N-{\bar f}_N\Vert\sim N^{-1/4}$ where ${\bar f}_N$ denotes an average over initial conditions, and we explain this asymptotic behavior in terms of the fluctuations of the so-called Neural Tangent Kernel that controls the dynamics of the output function. For the task of classification, we predict these fluctuations to increase the test error $\epsilon$ as $\epsilon_{N}-\epsilon_{\infty}\sim N^{-1/2} + \mathcal{O}( N^{-3/4})$: this prediction is consistent with our empirical results on the MNIST dataset and it explains the puzzling observation that the predictive power of deep networks improves as the number of fitting parameters grows. This asymptotic description breaks down at a so-called jamming transition which takes place at a critical $N=N^*$, below which the training error is non-zero. In the absence of regularization, we observe an apparent divergence $\Vert f_N\Vert\sim (N-N^*)^{-\alpha}$ and provide a simple argument suggesting $\alpha=1$, consistent with empirical observations. This result leads to a plausible explanation for the cusp in test error known to occur at $N^*$. In practice, our analysis suggests that optimal generalization can be reached by ensemble averaging output functions at $N$ fixed slightly above $N^*$.