 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Kernel Methods via Doubly Stochastic Gradients
Paper and Code
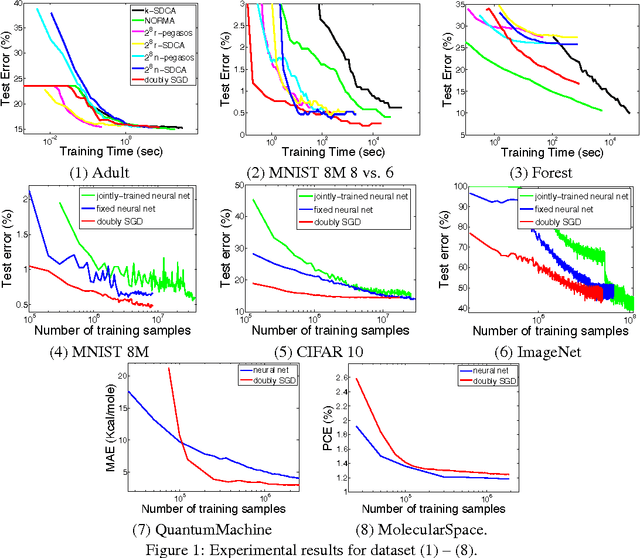
The general perception is that kernel methods are not scalable, and neural nets are the methods of choice for nonlinear learning problems. Or have we simply not tried hard enough for kernel methods? Here we propose an approach that scales up kernel methods using a novel concept called "doubly stochastic functional gradients". Our approach relies on the fact that many kernel methods can be expressed as convex optimization problems, and we solve the problems by making two unbiased stochastic approximations to the functional gradient, one using random training points and another using random functions associated with the kernel, and then descending using this noisy functional gradient. We show that a function produced by this procedure after $t$ iterations converges to the optimal function in the reproducing kernel Hilbert space in rate $O(1/t)$, and achieves a generalization performance of $O(1/\sqrt{t})$. This doubly stochasticity also allows us to avoid keeping the support vectors and to implement the algorithm in a small memory footprint, which is linear in number of iterations and independent of data dimension. Our approach can readily scale kernel methods up to the regimes which are dominated by neural nets. We show that our method can achieve competitive performance to neural nets in datasets such as 8 million handwritten digits from MNIST, 2.3 million energy materials from MolecularSpace, and 1 million photos from ImageNet.