 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLoop: A Self-Correction Continual Learning Loop for Recommender Systems
Paper and Code
Apr 24, 2022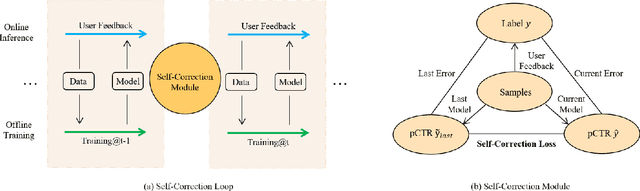

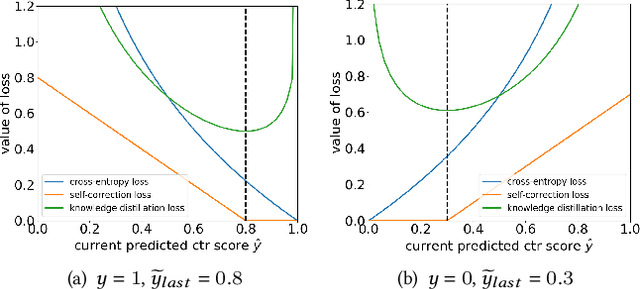

Deep learning-based recommendation has become a widely adopted technique in various online applications. Typically, a deployed model undergoes frequent re-training to capture users' dynamic behaviors from newly collected interaction logs. However, the current model training process only acquires users' feedbacks as labels, but fail to take into account the errors made in previous recommendations. Inspired by the intuition that humans usually reflect and learn from mistakes, in this paper, we attempt to build a self-correction learning loop (dubbed ReLoop) for recommender systems. In particular, a new customized loss is employed to encourage every new model version to reduce prediction errors over the previous model version during training. Our ReLoop learning framework enables a continual self-correction process in the long run and thus is expected to obtain better performance over existing training strategies. Both offline experiments and an online A/B test have been conducted to validate the effectiveness of ReLoop.