 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading-strategy Inspired Visual Representation Learning for Text-to-Video Retrieval
Paper and Code
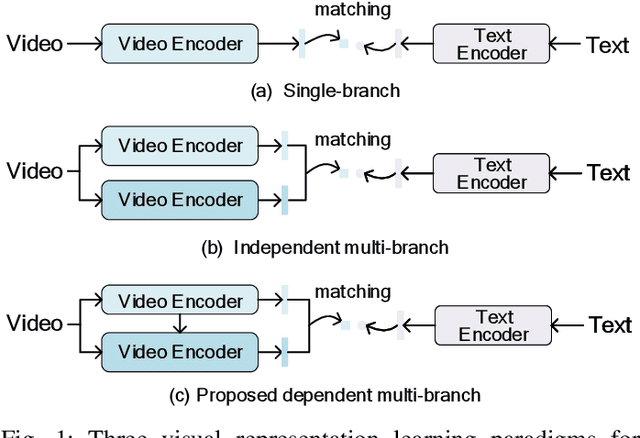
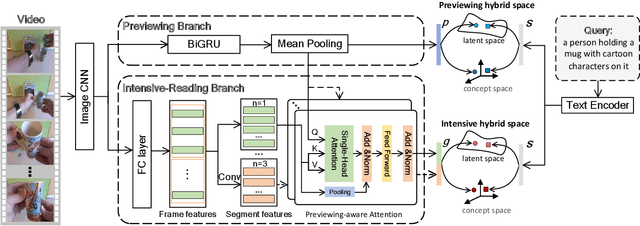
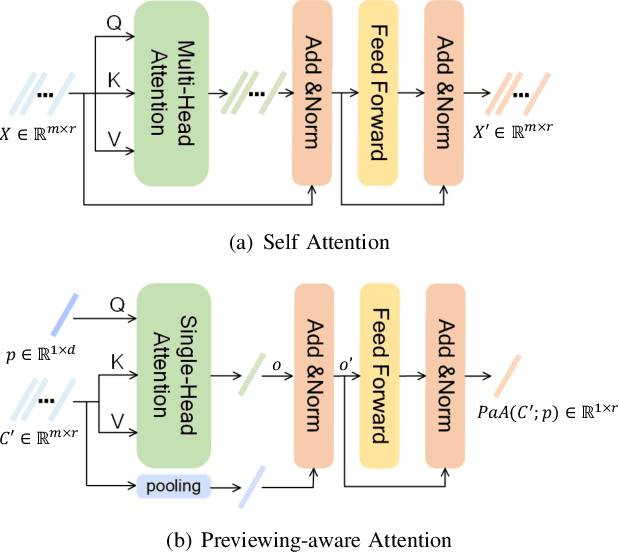
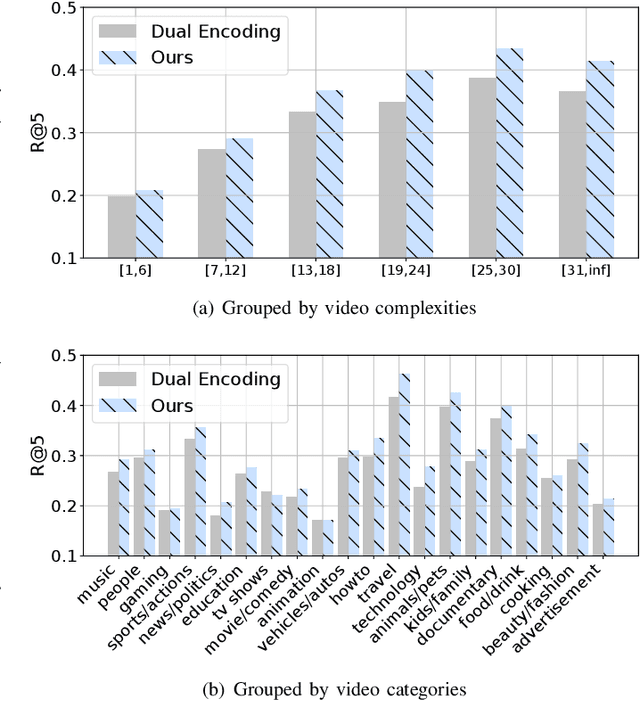
This paper aims for the task of text-to-video retrieval, where given a query in the form of a natural-language sentence, it is asked to retrieve videos which are semantically relevant to the given query, from a great number of unlabeled videos. The success of this task depends on cross-modal representation learning that projects both videos and sentences into common spaces for semantic similarity computation. In this work, we concentrate on video representation learning, an essential component for text-to-video retrieval. Inspired by the reading strategy of humans, we propose a Reading-strategy Inspired Visual Representation Learning (RIVRL) to represent videos, which consists of two branches: a previewing branch and an intensive-reading branch. The previewing branch is designed to briefly capture the overview information of videos, while the intensive-reading branch is designed to obtain more in-depth information. Moreover, the intensive-reading branch is aware of the video overview captured by the previewing branch. Such holistic information is found to be useful for the intensive-reading branch to extract more fine-grained features. Extensive experiments on three datasets are conducted, where our model RIVRL achieves a new state-of-the-art on TGIF and VATEX. Moreover, on MSR-VTT, our model using two video features shows comparable performance to the state-of-the-art using seven video features and even outperforms models pre-trained on the large-scale HowTo100M dataset.