 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaw-to-End Name Entity Recognition in Social Media
Paper and Code



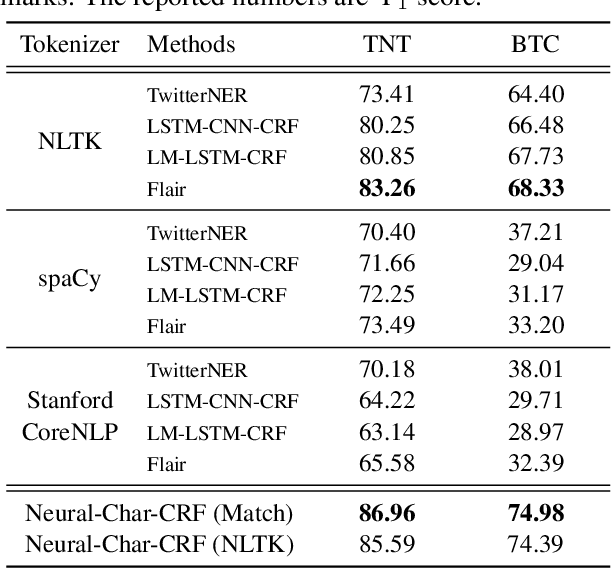
Taking word sequences as the input, typical named entity recognition (NER) models neglect errors from pre-processing (e.g., tokenization). However, these errors can influence the model performance greatly, especially for noisy texts like tweets. Here, we introduce Neural-Char-CRF, a raw-to-end framework that is more robust to pre-processing errors. It takes raw character sequences as inputs and makes end-to-end predictions. Word embedding and contextualized representation models are further tailored to capture textual signals for each character instead of each word. Our model neither requires the conversion from character sequences to word sequences, nor assumes tokenizer can correctly detect all word boundaries. Moreover, we observe our model performance remains unchanged after replacing tokenization with string matching, which demonstrates its potential to be tokenization-free. Extensive experimental results on two public datasets demonstrate the superiority of our proposed method over the state of the art. The implementations and datasets are made available at: https://github.com/LiyuanLucasLiu/Raw-to-End.