 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Filter Size in Convolutional Neural Networks for Facial Action Unit Recognition
Paper and Code
Nov 22, 2017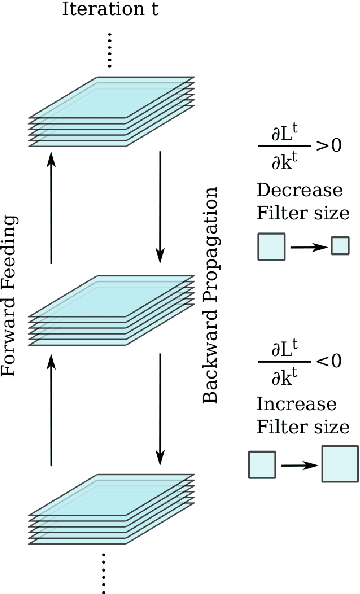
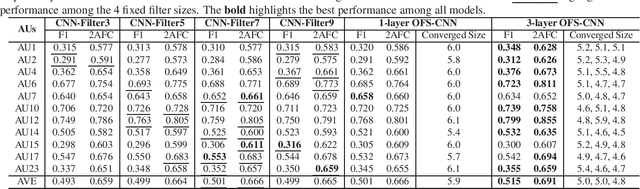
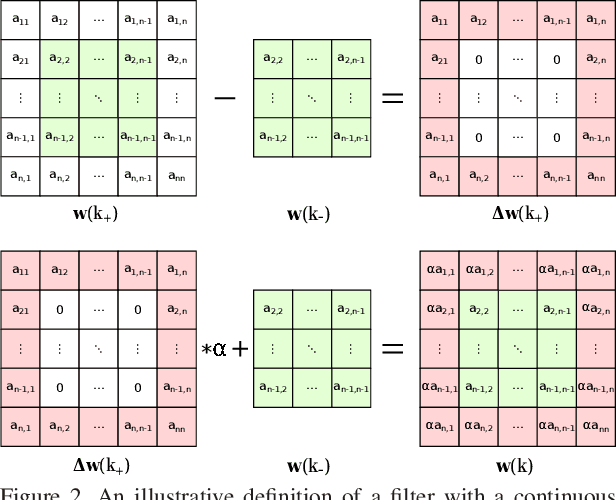
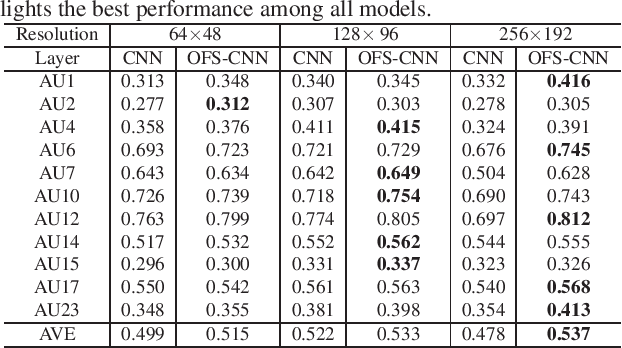
Recognizing facial action units (AUs) during spontaneous facial displays is a challenging problem. Most recently, Convolutional Neural Networks (CNNs) have shown promise for facial AU recognition, where predefined and fixed convolution filter sizes are employed. In order to achieve the best performance, the optimal filter size is often empirically found by conducting extensive experimental validation. Such a training process suffers from expensive training cost, especially as the network becomes deeper. This paper proposes a novel Optimized Filter Size CNN (OFS-CNN), where the filter sizes and weights of all convolutional layers are learned simultaneously from the training data along with learning convolution filters. Specifically, the filter size is defined as a continuous variable, which is optimized by minimizing the training loss. Experimental results on two AU-coded spontaneous databases have shown that the proposed OFS-CNN is capable of estimating optimal filter size for varying image resolution and outperforms traditional CNNs with the best filter size obtained by exhaustive search. The OFS-CNN also beats the CNN using multiple filter sizes and more importantly, is much more efficient during testing with the proposed forward-backward propagation algorithm.