 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgenocaps: novel object captioning at scale
Paper and Code

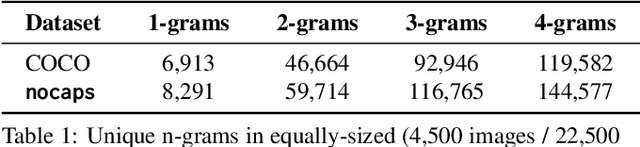
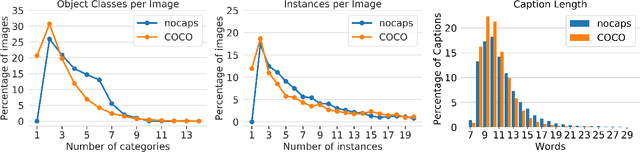
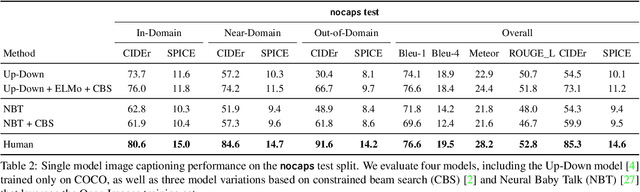
Image captioning models have achieved impressive results on datasets containing limited visual concepts and large amounts of paired image-caption training data. However, if these models are to ever function in the wild, a much larger variety of visual concepts must be learned, ideally from less supervision. To encourage the development of image captioning models that can learn visual concepts from alternative data sources, such as object detection datasets, we present the first large-scale benchmark for this task. Dubbed 'nocaps', for novel object captioning at scale, our benchmark consists of 166,100 human-generated captions describing 15,100 images from the Open Images validation and test sets. The associated training data consists of COCO image-caption pairs, plus Open Images image-level labels and object bounding boxes. Since Open Images contains many more classes than COCO, more than 500 object classes seen in test images have no training captions (hence, nocaps). We evaluate several existing approaches to novel object captioning on our challenging benchmark. In automatic evaluations these approaches show modest improvements over a strong baseline trained only on image-caption data. However, even when using ground-truth object detections, the results are significantly weaker than our human baseline - indicating substantial room for improvement.