 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCLS: Neural Cross-Lingual Summarization
Paper and Code
Aug 31, 2019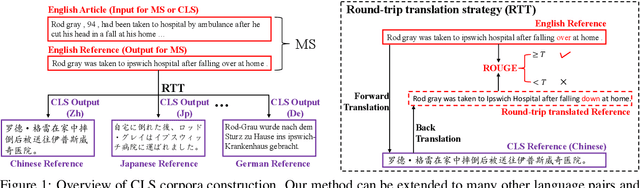



Cross-lingual summarization (CLS) is the task to produce a summary in one particular language for a source document in a different language. Existing methods simply divide this task into two steps: summarization and translation, leading to the problem of error propagation. To handle that, we present an end-to-end CLS framework, which we refer to as Neural Cross-Lingual Summarization (NCLS), for the first time. Moreover, we propose to further improve NCLS by incorporating two related tasks, monolingual summarization and machine translation, into the training process of CLS under multi-task learning. Due to the lack of supervised CLS data, we propose a round-trip translation strategy to acquire two high-quality large-scale CLS datasets based on existing monolingual summarization datasets. Experimental results have shown that our NCLS achieves remarkable improvement over traditional pipeline methods on both English-to-Chinese and Chinese-to-English CLS human-corrected test sets. In addition, NCLS with multi-task learning can further significantly improve the quality of generated summaries. We make our dataset and code publicly available here: http://www.nlpr.ia.ac.cn/cip/dataset.htm.