 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVCNet: Multiview Contrastive Network for Unsupervised Representation Learning for 3D CT Lesions
Paper and Code
Aug 18, 2021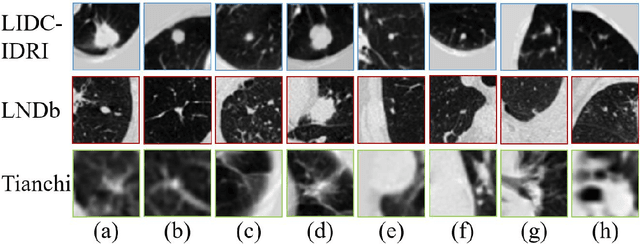
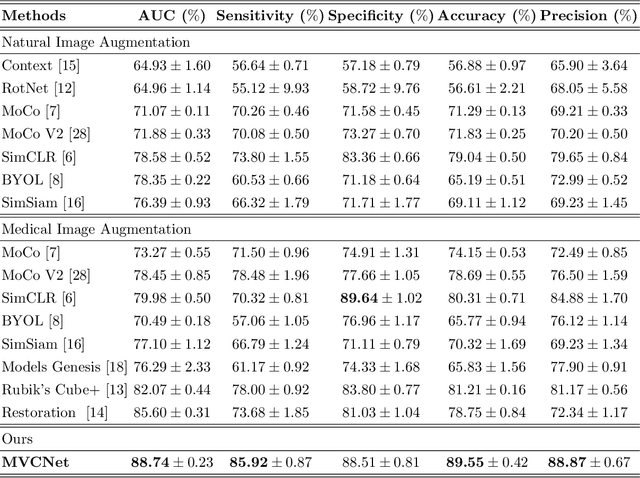
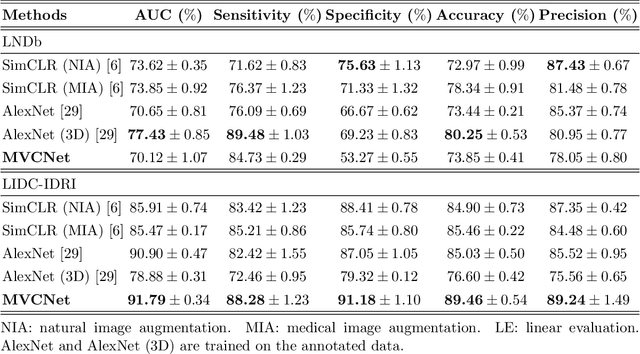
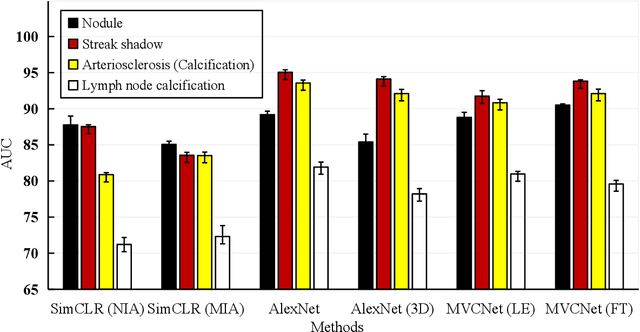
\emph{Objective and Impact Statement}. With the renaissance of deep learning, automatic diagnostic systems for computed tomography (CT) have achieved many successful applications. However, they are mostly attributed to careful expert annotations, which are often scarce in practice. This drives our interest to the unsupervised representation learning. \emph{Introduction}. Recent studies have shown that self-supervised learning is an effective approach for learning representations, but most of them rely on the empirical design of transformations and pretext tasks. \emph{Methods}. To avoid the subjectivity associated with these methods, we propose the MVCNet, a novel unsupervised three dimensional (3D) representation learning method working in a transformation-free manner. We view each 3D lesion from different orientations to collect multiple two dimensional (2D) views. Then, an embedding function is learned by minimizing a contrastive loss so that the 2D views of the same 3D lesion are aggregated, and the 2D views of different lesions are separated. We evaluate the representations by training a simple classification head upon the embedding layer. \emph{Results}. Experimental results show that MVCNet achieves state-of-the-art accuracies on the LIDC-IDRI (89.55\%), LNDb (77.69\%) and TianChi (79.96\%) datasets for \emph{unsupervised representation learning}. When fine-tuned on 10\% of the labeled data, the accuracies are comparable to the supervised learning model (89.46\% vs. 85.03\%, 73.85\% vs. 73.44\%, 83.56\% vs. 83.34\% on the three datasets, respectively). \emph{Conclusion}. Results indicate the superiority of MVCNet in \emph{learning representations with limited annotations}.