 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Transformers Excel at Class-agnostic Object Detection
Paper and Code

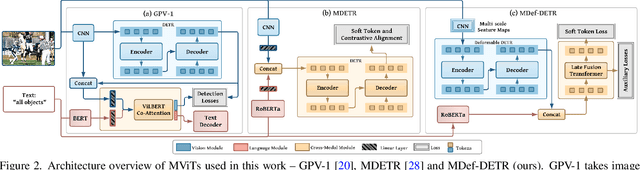

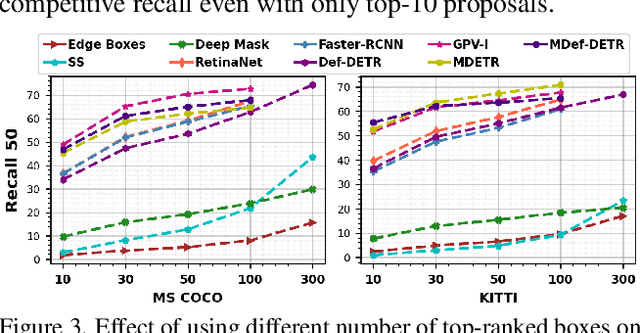
What constitutes an object? This has been a long-standing question in computer vision. Towards this goal, numerous learning-free and learning-based approaches have been developed to score objectness. However, they generally do not scale well across new domains and for unseen objects. In this paper, we advocate that existing methods lack a top-down supervision signal governed by human-understandable semantics. To bridge this gap, we explore recent Multi-modal Vision Transformers (MViT) that have been trained with aligned image-text pairs. Our extensive experiments across various domains and novel objects show the state-of-the-art performance of MViTs to localize generic objects in images. Based on these findings, we develop an efficient and flexible MViT architecture using multi-scale feature processing and deformable self-attention that can adaptively generate proposals given a specific language query. We show the significance of MViT proposals in a diverse range of applications including open-world object detection, salient and camouflage object detection, supervised and self-supervised detection tasks. Further, MViTs offer enhanced interactability with intelligible text queries. Code: https://git.io/J1HPY.