 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-initialization Optimization Network for Accurate 3D Human Pose and Shape Estimation
Paper and Code
Dec 24, 2021
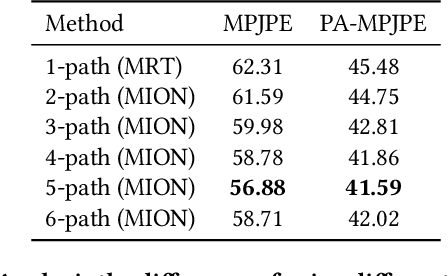

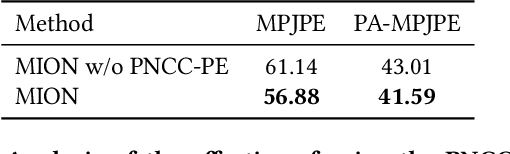
3D human pose and shape recovery from a monocular RGB image is a challenging task. Existing learning based methods highly depend on weak supervision signals, e.g. 2D and 3D joint location, due to the lack of in-the-wild paired 3D supervision. However, considering the 2D-to-3D ambiguities existed in these weak supervision labels, the network is easy to get stuck in local optima when trained with such labels. In this paper, we reduce the ambituity by optimizing multiple initializations. Specifically, we propose a three-stage framework named Multi-Initialization Optimization Network (MION). In the first stage, we strategically select different coarse 3D reconstruction candidates which are compatible with the 2D keypoints of input sample. Each coarse reconstruction can be regarded as an initialization leads to one optimization branch. In the second stage, we design a mesh refinement transformer (MRT) to respectively refine each coarse reconstruction result via a self-attention mechanism. Finally, a Consistency Estimation Network (CEN) is proposed to find the best result from mutiple candidates by evaluating if the visual evidence in RGB image matches a given 3D reconstruction. Experiments demonstrate that our Multi-Initialization Optimization Network outperforms existing 3D mesh based methods on multiple public benchmarks.