 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDERank: A Masked Document Embedding Rank Approach for Unsupervised Keyphrase Extraction
Paper and Code

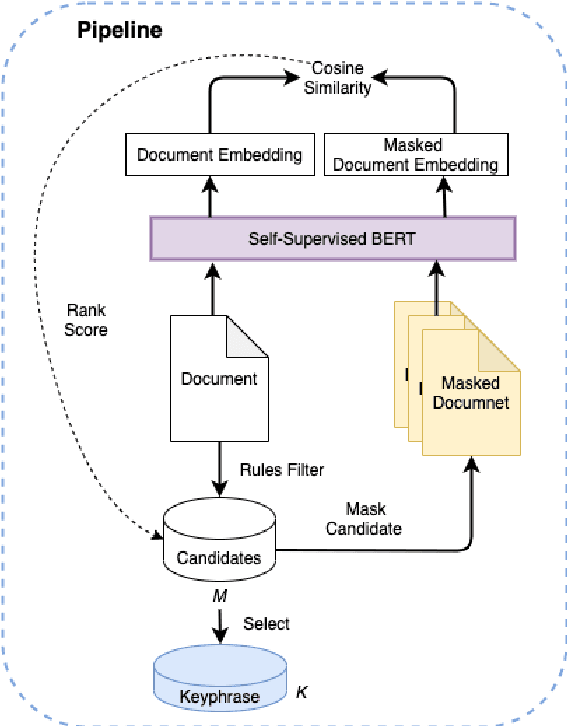
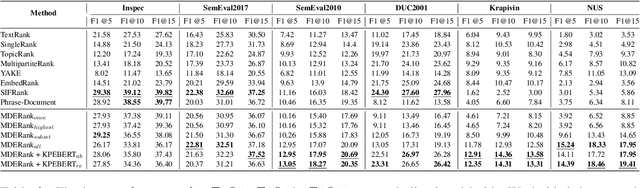
Keyphrases are phrases in a document providing a concise summary of core content, helping readers to understand what the article is talking about in a minute. However, existing unsupervised works are not robust enough to handle various types of documents owing to the mismatch of sequence length for comparison. In this paper, we propose a novel unsupervised keyword extraction method by leveraging the BERT-based model to select and rank candidate keyphrases with a MASK strategy. In addition, we further enhance the model, denoted as Keyphrases Extraction BERT (KPEBERT), via designing a compatible self-supervised task and conducting a contrast learning. We conducted extensive experimental evaluation to demonstrate the superiority and robustness of the proposed method as well as the effectiveness of KPEBERT.