 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARM: Unlocking the Future of Recommendation Systems through Memory Augmentation and Scalable Complexity
Paper and Code
Nov 14, 2024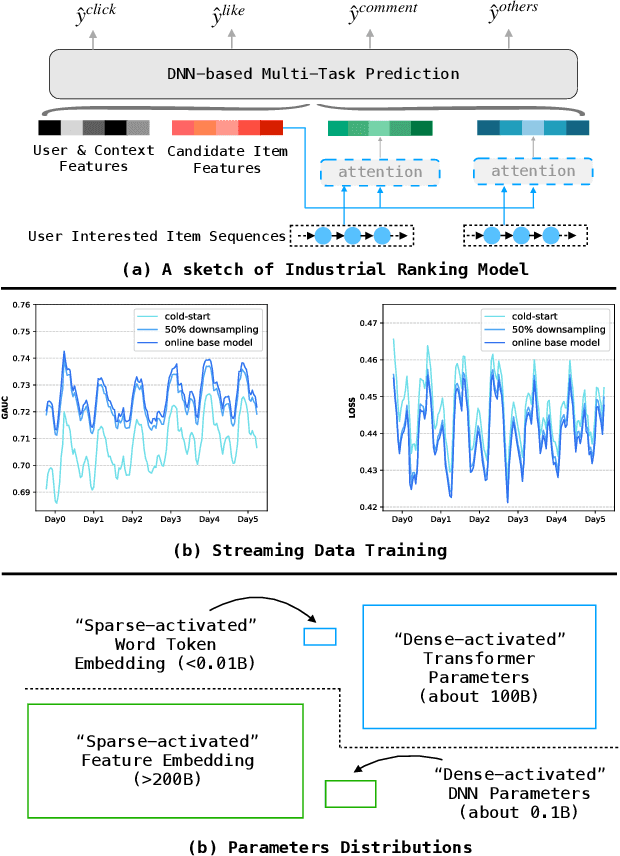
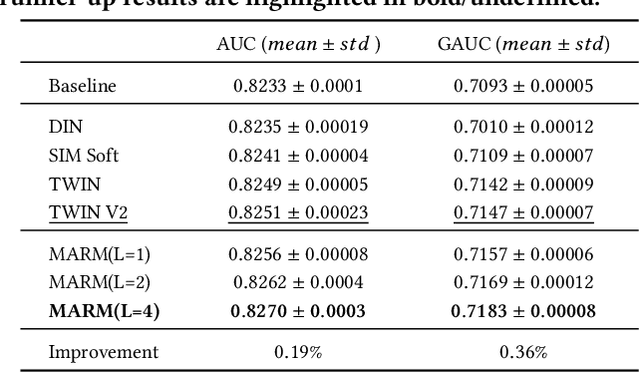
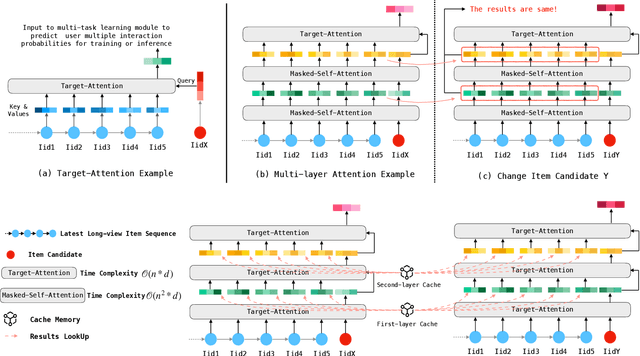
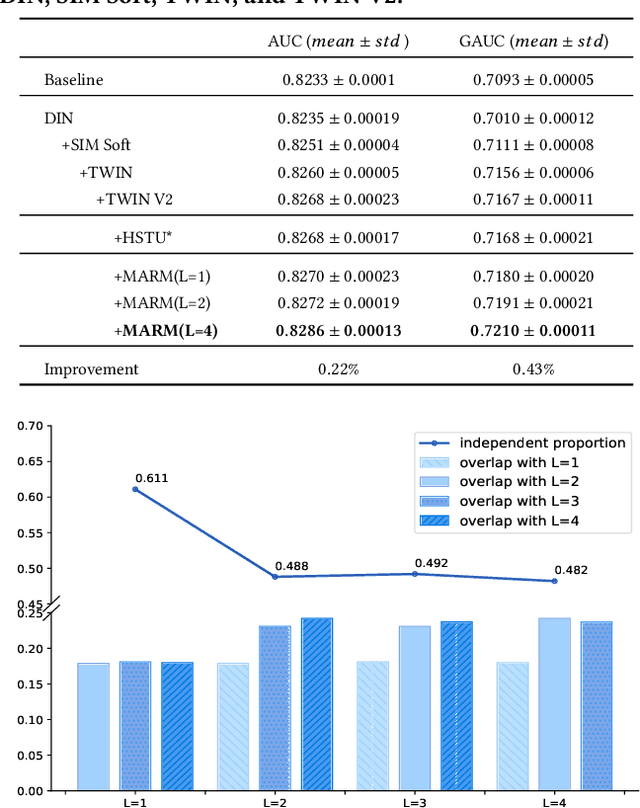
Scaling-law has guided the language model designing for past years, however, it is worth noting that the scaling laws of NLP cannot be directly applied to RecSys due to the following reasons: (1) The amount of training samples and model parameters is typically not the bottleneck for the model. Our recommendation system can generate over 50 billion user samples daily, and such a massive amount of training data can easily allow our model parameters to exceed 200 billion, surpassing many LLMs (about 100B). (2) To ensure the stability and robustness of the recommendation system, it is essential to control computational complexity FLOPs carefully. Considering the above differences with LLM, we can draw a conclusion that: for a RecSys model, compared to model parameters, the computational complexity FLOPs is a more expensive factor that requires careful control. In this paper, we propose our milestone work, MARM (Memory Augmented Recommendation Model), which explores a new cache scaling-laws successfully.