 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoad-balanced Gather-scatter Patterns for Sparse Deep Neural Networks
Paper and Code
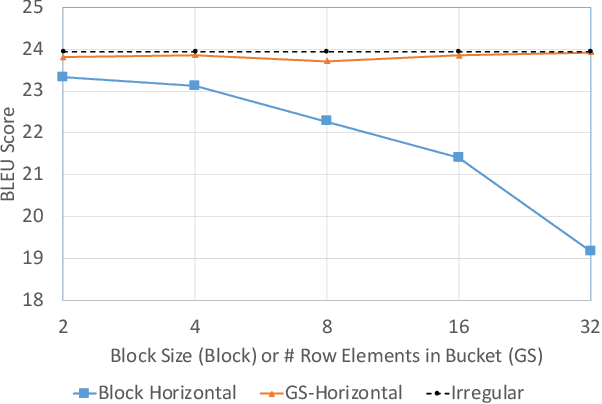
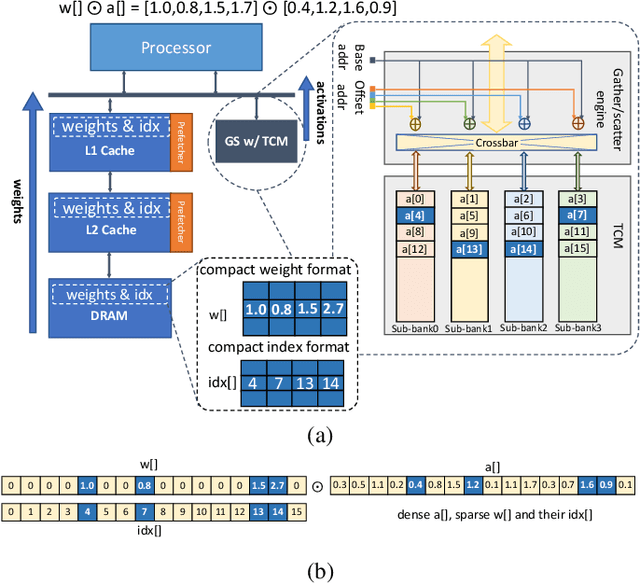

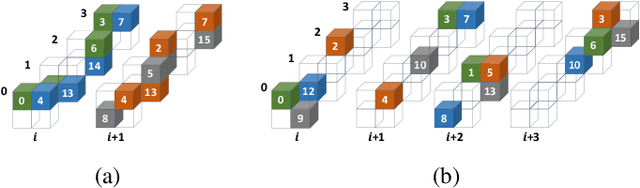
Deep neural networks (DNNs) have been proven to be effective in solving many real-life problems, but its high computation cost prohibits those models from being deployed to edge devices. Pruning, as a method to introduce zeros to model weights, has shown to be an effective method to provide good trade-offs between model accuracy and computation efficiency, and is a widely-used method to generate compressed models. However, the granularity of pruning makes important trade-offs. At the same sparsity level, a coarse-grained structured sparse pattern is more efficient on conventional hardware but results in worse accuracy, while a fine-grained unstructured sparse pattern can achieve better accuracy but is inefficient on existing hardware. On the other hand, some modern processors are equipped with fast on-chip scratchpad memories and gather/scatter engines that perform indirect load and store operations on such memories. In this work, we propose a set of novel sparse patterns, named gather-scatter (GS) patterns, to utilize the scratchpad memories and gather/scatter engines to speed up neural network inferences. Correspondingly, we present a compact sparse format. The proposed set of sparse patterns, along with a novel pruning methodology, address the load imbalance issue and result in models with quality close to unstructured sparse models and computation efficiency close to structured sparse models. Our experiments show that GS patterns consistently make better trade-offs between accuracy and computation efficiency compared to conventional structured sparse patterns. GS patterns can reduce the runtime of the DNN components by two to three times at the same accuracy levels. This is confirmed on three different deep learning tasks and popular models, namely, GNMT for machine translation, ResNet50 for image recognition, and Japser for acoustic speech recognition.