 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear attention is (maybe) all you need (to understand transformer optimization)
Paper and Code
Oct 02, 2023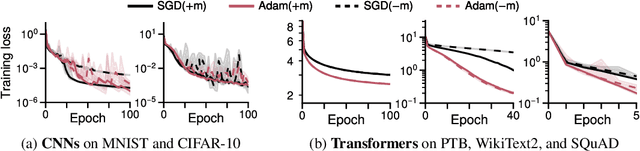
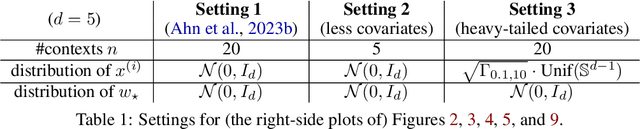
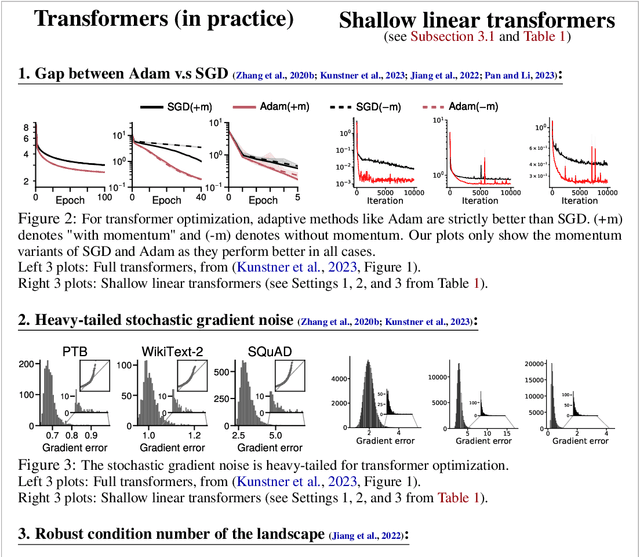

Transformer training is notoriously difficult, requiring a careful design of optimizers and use of various heuristics. We make progress towards understanding the subtleties of training transformers by carefully studying a simple yet canonical linearized shallow transformer model. Specifically, we train linear transformers to solve regression tasks, inspired by J. von Oswald et al. (ICML 2023), and K. Ahn et al. (NeurIPS 2023). Most importantly, we observe that our proposed linearized models can reproduce several prominent aspects of transformer training dynamics. Consequently, the results obtained in this paper suggest that a simple linearized transformer model could actually be a valuable, realistic abstraction for understanding transformer optimization.