 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reward Functions from Diverse Sources of Human Feedback: Optimally Integrating Demonstrations and Preferences
Paper and Code
Jun 24, 2020

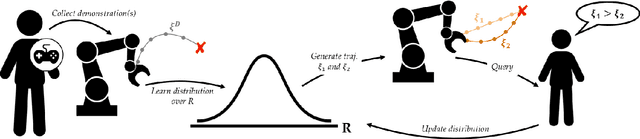

Reward functions are a common way to specify the objective of a robot. As designing reward functions can be extremely challenging, a more promising approach is to directly learn reward functions from human teachers. Importantly, humans provide data in a variety of forms: these include instructions (e.g., natural language), demonstrations, (e.g., kinesthetic guidance), and preferences (e.g., comparative rankings). Prior research has independently applied reward learning to each of these different data sources. However, there exist many domains where some of these information sources are not applicable or inefficient -- while multiple sources are complementary and expressive. Motivated by this general problem, we present a framework to integrate multiple sources of information, which are either passively or actively collected from human users. In particular, we present an algorithm that first utilizes user demonstrations to initialize a belief about the reward function, and then proactively probes the user with preference queries to zero-in on their true reward. This algorithm not only enables us combine multiple data sources, but it also informs the robot when it should leverage each type of information. Further, our approach accounts for the human's ability to provide data: yielding user-friendly preference queries which are also theoretically optimal. Our extensive simulated experiments and user studies on a Fetch mobile manipulator demonstrate the superiority and the usability of our integrated framework.